Protein Structure Collector
One-shot UniProt + PDB + AlphaFold structure collection.
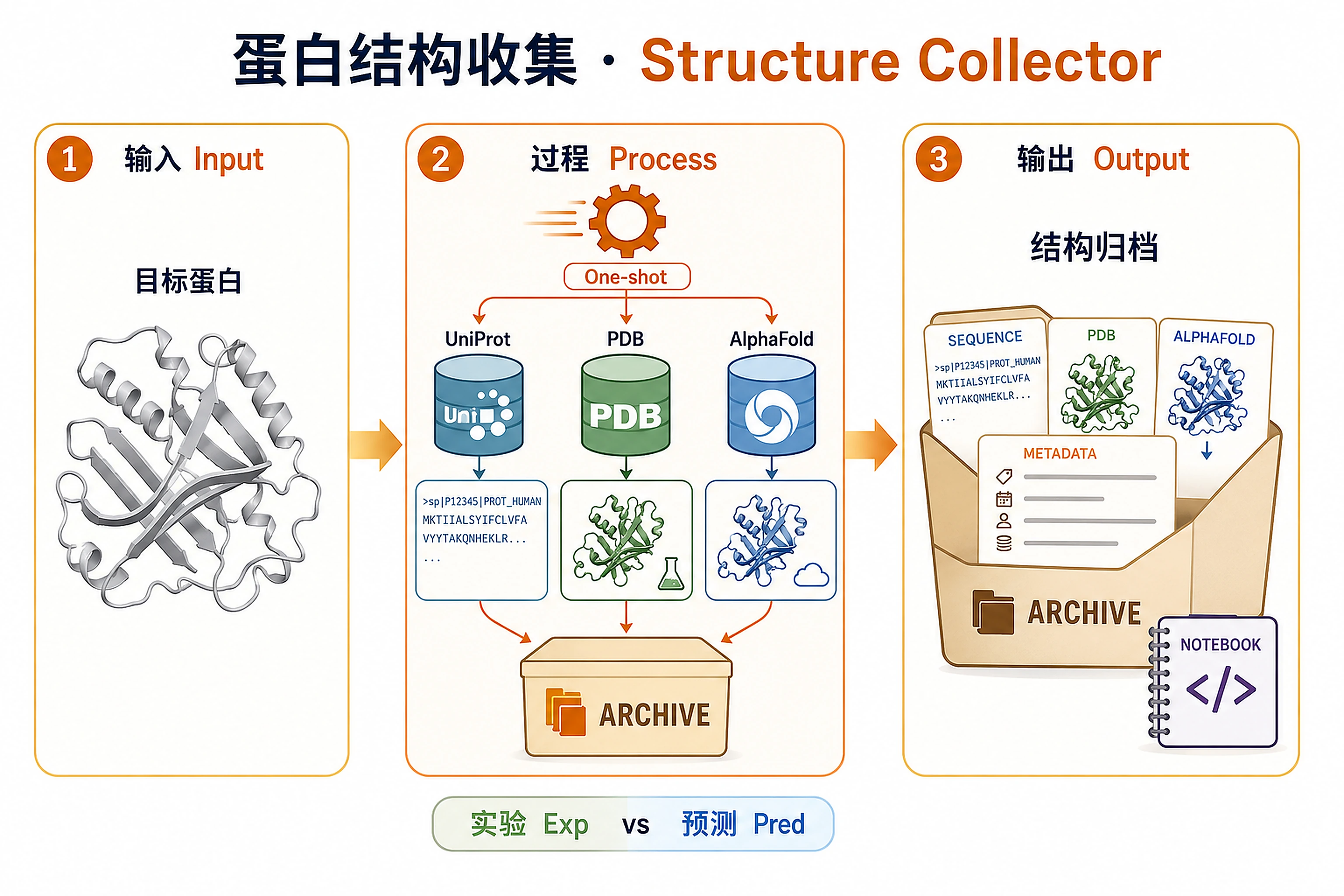
Overview
Problem. Systematically archive sequence, structure and metadata first.
Learning goals
- Experimental (PDB) vs predicted (AlphaFold)
- Make data collection reproducible
Figures
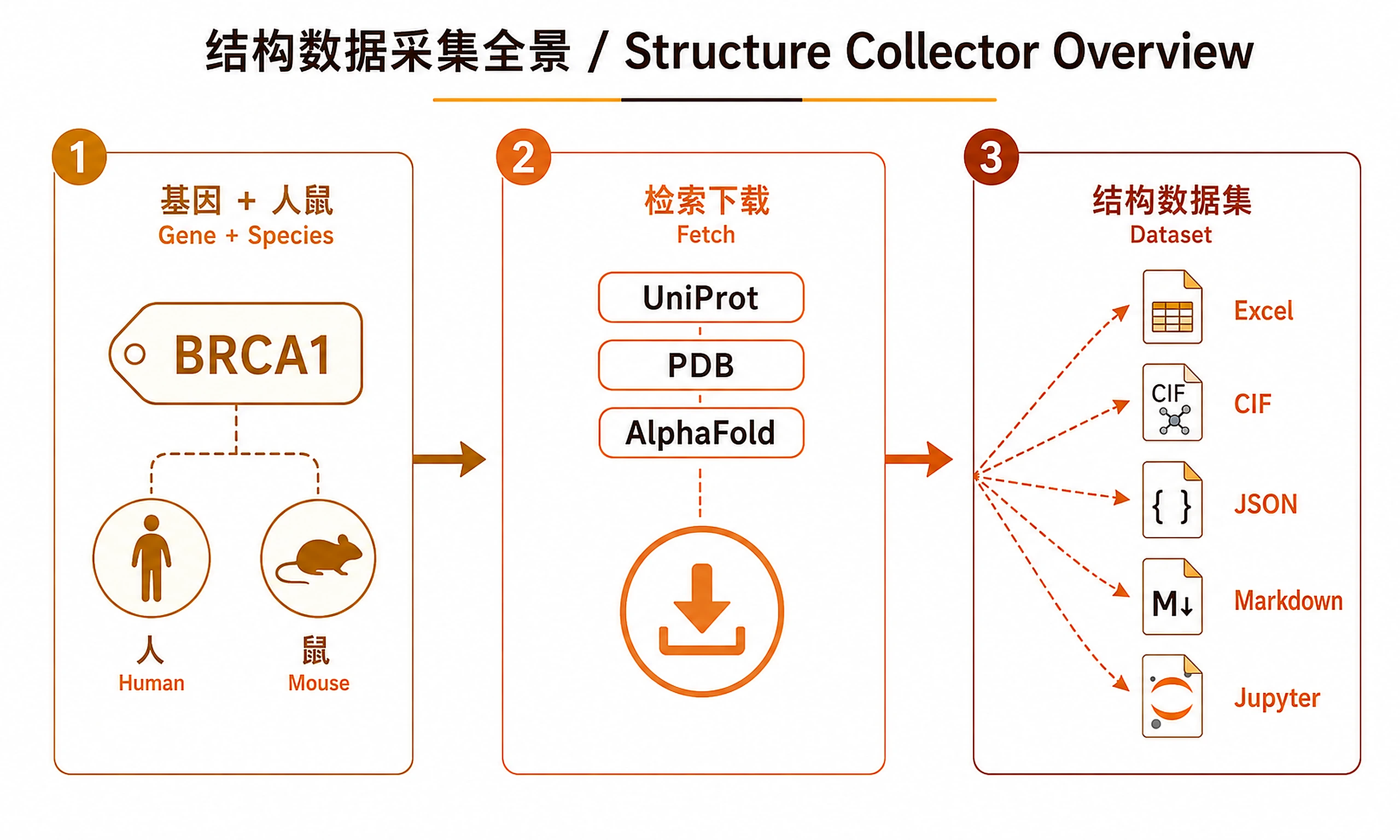
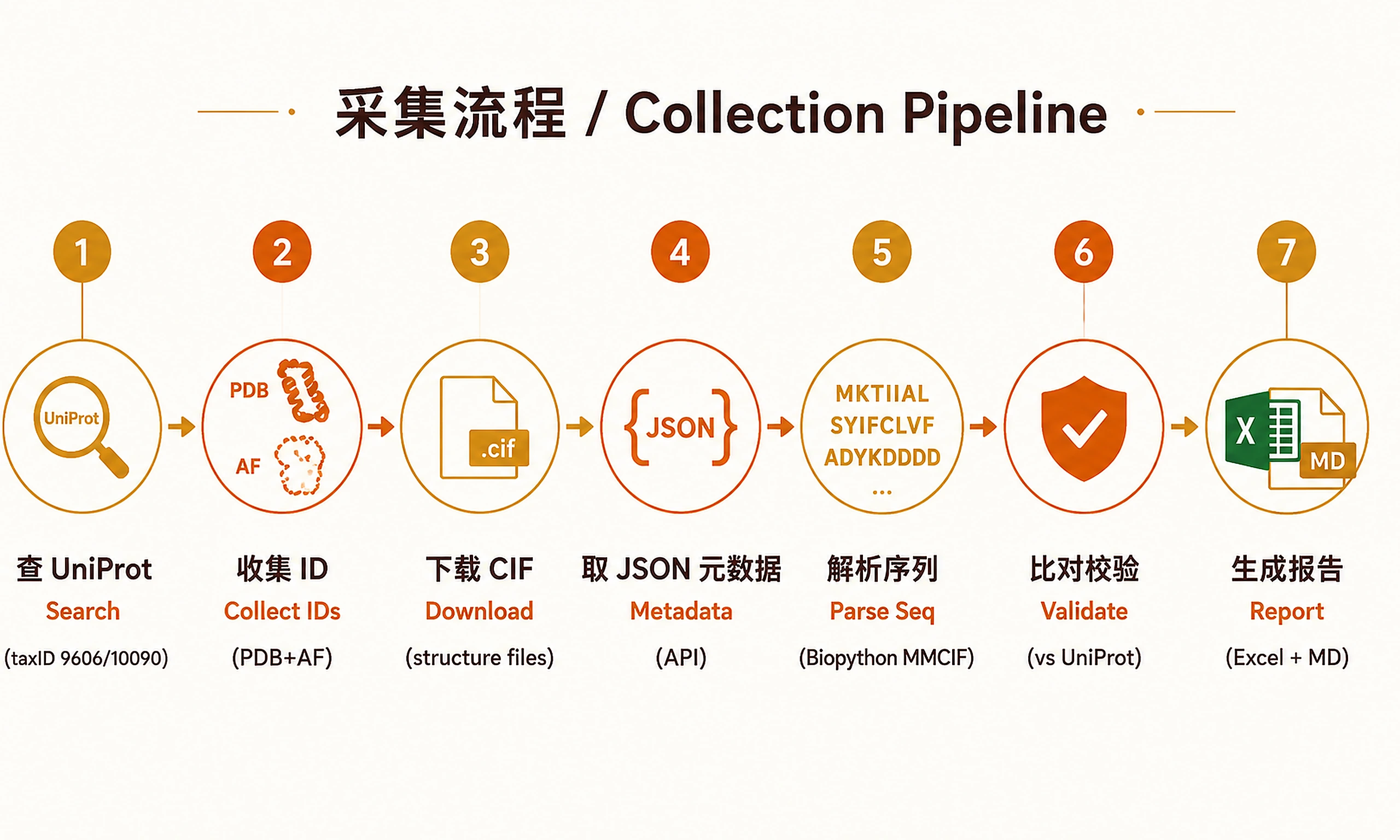
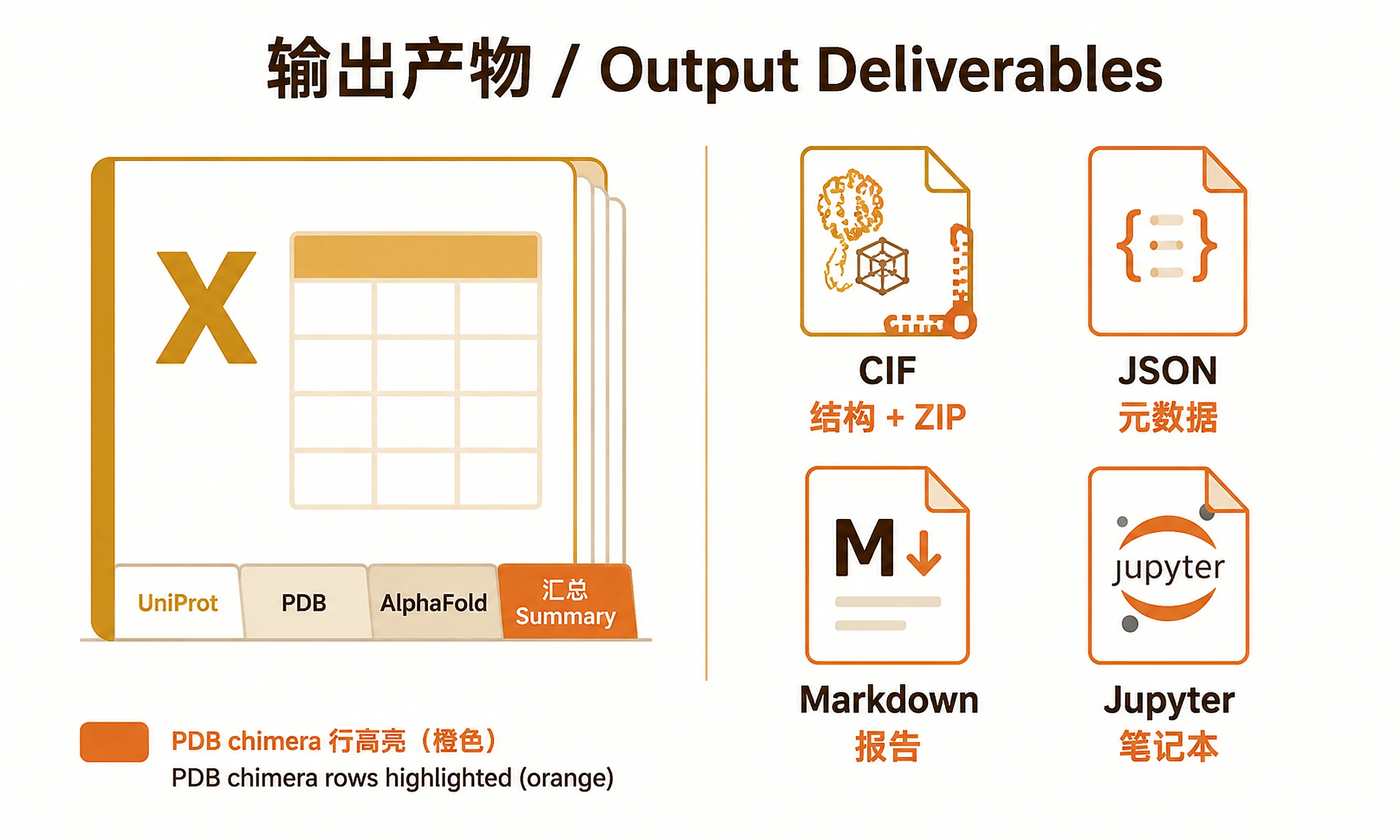
Tutorial
Scope
For a given gene/protein name, collect all human (Homo sapiens, taxID 9606) and mouse (Mus musculus, taxID 10090) entries from UniProt, download all associated PDB and AlphaFold CIF structure files, fetch full-field JSON metadata from official APIs, generate two structured Excel files, write a comprehensive Markdown report, and deliver a reproducible Jupyter notebook.
Does NOT: perform structural analysis, molecular docking, sequence alignment, or phylogenetic analysis. Does not cover species other than human and mouse unless explicitly requested.
Inputs
| Input | Type | Example | Notes |
|---|---|---|---|
| Gene/protein name | String | GPR52, ADORA2A, DRD2 |
Gene symbol preferred; UniProt also accepts protein names |
| Output directory | Path | ./output |
Created automatically if absent |
Outputs
| File | Description |
|---|---|
{GENE}_Human_Mouse_Uniport.xlsx |
UniProt entries (all human + mouse), with sequences, PDB IDs, AlphaFold IDs, URLs |
{GENE}_Human_Mouse_Uniport_PDB_AlphaFold.xlsx |
Comprehensive 4-sheet Excel (see Sheet structure below) |
cif_files/{GENE}_{Species}_PDB_{PDB_ID}.cif |
PDB mmCIF structure files |
cif_files/{GENE}_{Species}_AF_{AF_ID}.cif |
AlphaFold mmCIF structure files (current model version) |
{GENE}_Human_Mouse_CIF_files.zip |
ZIP archive of all CIF files |
json/{Species}_PDB_{ID}_entry.json |
RCSB PDB entry metadata (resolution, method, citation, etc.) |
json/{Species}_PDB_{ID}_polymer_entity.json |
Polymer chain details, sequence, UniProt mapping |
json/{Species}_PDB_{ID}_assembly.json |
Biological assembly information |
json/{Species}_AF_{Accession}_prediction.json |
AlphaFold prediction metadata (pLDDT, PAE URL, MSA URL, etc.) |
json/{GENE}_json_index.json |
Master index of all JSON files |
{GENE}_Human_Mouse_Data_Report.md |
Comprehensive Markdown report |
notebook_template.ipynb |
Reproducible Jupyter notebook (all steps, parameterized) |
Excel Sheet Structure
Sheet 1 — UniProt_Sequences Columns: UniProt_Accession, Entry_Type, UniProt_ID, Protein_Name, Organism, Species, TaxID, Gene_Name, Sequence_Length_aa, Sequence, PDB_IDs, AlphaFold_ID, UniProt_URL, PDB_URLs, AlphaFold_URL
Sheet 2 — PDB_Sequences Columns: PDB_ID, Species, UniProt_Accession, Chain_IDs, Is_Chimera, Chimera_Partners_UniProt, Target_Protein_UniProt_Coverage, Target_Protein_Seq_From_CIF, Target_Protein_Seq_Length_aa, Full_Chain_Seq_In_Structure, Full_Chain_Seq_Length_aa, RCSB_URL, CIF_File, Note (Chimera rows highlighted in orange)
Sheet 3 — AlphaFold_Sequences Columns: AlphaFold_ID, UniProt_Accession, UniProt_ID, Species, Chain_ID, Sequence, Sequence_Length_aa, Global_pLDDT, Model_Version, Model_Created_Date, Fraction_pLDDT_VeryHigh/Confident/Low/VeryLow, CIF_URL, PAE_URL, MSA_URL, AlphaMissense_URL, AlphaFold_URL, CIF_File
Sheet 4 — Sequence_Summary All sequences from all sources in one table for easy comparison: Source, ID, Species, Entry_Type, Sequence_Length_aa, Sequence, Coverage, Notes
File Naming Conventions
| File type | Convention | Example |
|---|---|---|
| PDB CIF | {GENE}_{Species}_PDB_{PDB_ID}.cif |
GPR52_Human_PDB_6LI0.cif |
| AlphaFold CIF | {GENE}_{Species}_AF_{AF_ID}.cif |
GPR52_Mouse_AF_AF-P0C5J4-F1.cif |
| PDB JSON (entry) | {Species}_PDB_{ID}_entry.json |
Human_PDB_6LI0_entry.json |
| PDB JSON (polymer) | {Species}_PDB_{ID}_polymer_entity.json |
Human_PDB_6LI0_polymer_entity.json |
| PDB JSON (assembly) | {Species}_PDB_{ID}_assembly.json |
Human_PDB_6LI0_assembly.json |
| AlphaFold JSON | {Species}_AF_{Accession}_prediction.json |
Mouse_AF_P0C5J4_prediction.json |
Workflow Steps
Step 1 — Search UniProt for all human and mouse entries
Query https://rest.uniprot.org/uniprotkb/search with:
query=gene:{GENE} AND organism_id:9606(human)query=gene:{GENE} AND organism_id:10090(mouse)
Parse each entry to extract: accession, entry type (Swiss-Prot/TrEMBL), protein name, organism, gene name, sequence, PDB cross-references, AlphaFoldDB cross-references.
Why: UniProt is the authoritative source for protein identity and cross-references to structural databases. Querying by taxID ensures species specificity.
Step 2 — Collect all PDB IDs and AlphaFold IDs
Extract unique PDB IDs and AlphaFold IDs from the UniProt cross-references. Map each PDB ID to its source species.
Step 3 — Download PDB CIF files
For each PDB ID, download from https://files.rcsb.org/download/{PDB_ID}.cif.
Save as {GENE}_{Species}_PDB_{PDB_ID}.cif.
Why: mmCIF is the current standard format for macromolecular structures (wwPDB). It contains atomic coordinates, sequence, experimental parameters, and all metadata.
Step 4 — Download AlphaFold CIF files
For each AlphaFold entry:
- Query
https://alphafold.ebi.ac.uk/api/prediction/{UniProt_Accession}to get the currentcifUrl(model version changes over time — currently v6 as of 2025). - Download the CIF from the returned URL.
- Save as
{GENE}_{Species}_AF_{AF_ID}.cif.
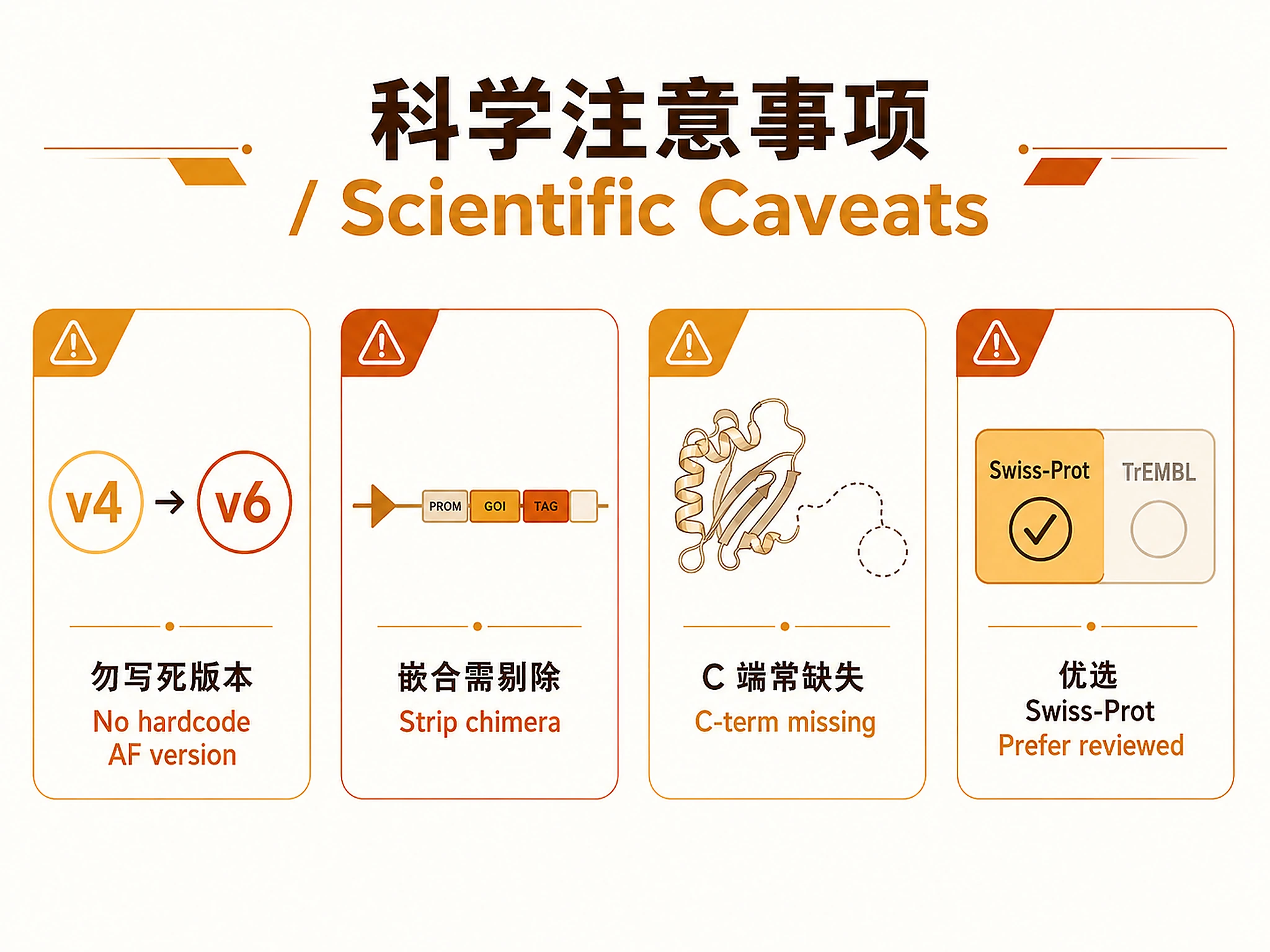
Critical: Never hardcode the AlphaFold model version (e.g., v4). Always resolve the current URL via the API
cifUrlfield. v4 URLs are now obsolete (404).
Step 5 — Package CIF files into ZIP
Compress all CIF files into {GENE}_Human_Mouse_CIF_files.zip.
Step 6 — Download PDB JSON metadata (RCSB PDB Data API)
For each PDB ID, fetch three endpoints:
/core/entry/{PDB_ID}→ resolution, method, R-factor, citation, authors, deposit date/core/polymer_entity/{PDB_ID}/1→ chain sequence, UniProt mapping, mutations, membrane annotation/core/assembly/{PDB_ID}/1→ biological assembly, symmetry
Save with species prefix: {Species}_PDB_{ID}_{type}.json.
Step 7 — Download AlphaFold JSON metadata
For each UniProt accession, fetch https://alphafold.ebi.ac.uk/api/prediction/{accession}.
Save as {Species}_AF_{Accession}_prediction.json.
Key fields captured: entryId, gene, uniprotId, taxId, organism, sequence, latestVersion, modelCreatedDate, globalMetricValue (pLDDT), fractionPlddt*, cifUrl, paeDocUrl, msaUrl, plddtDocUrl, amAnnotationsUrl (AlphaMissense), isReviewed.
Step 8 — Generate master JSON index
Write {GENE}_json_index.json listing all downloaded JSON files with their source APIs
and key summary fields.
Step 9 — Extract protein sequences from CIF files
Use Biopython MMCIF2Dict to parse each CIF file:
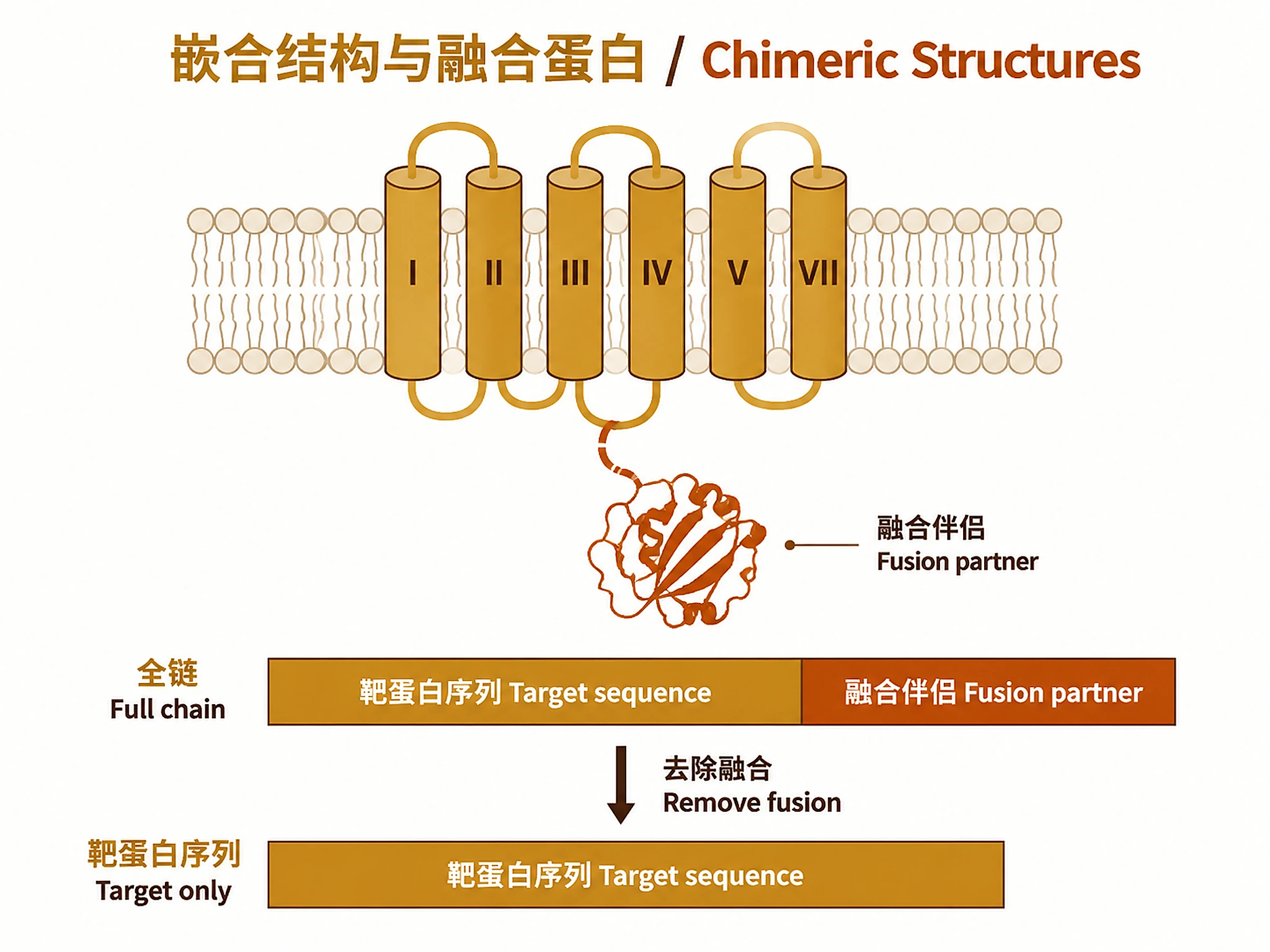
PDB CIF (may contain chimeric chains):
- Read
_entity_poly.pdbx_seq_one_letter_code_can→ full chain sequence - Read
_struct_ref.pdbx_db_accession→ identify which entity belongs to the target protein - Read
_struct_ref.pdbx_seq_one_letter_code→ target protein residues only - Read
_struct_ref_seq.db_align_beg/end→ UniProt coverage coordinates - Flag chimeric structures (fusion proteins inserted for crystallization)
AlphaFold CIF (always single-chain, no chimeras):
- Read
_entity_poly.pdbx_seq_one_letter_code_can→ full sequence - Read
_ma_qa_metric_global.metric_value→ global pLDDT
Why this matters: X-ray crystal structures of GPCRs and other membrane proteins frequently use fusion proteins (e.g., Flavodoxin, T4 lysozyme, BRIL) inserted into intracellular loops to aid crystallization. The full chain sequence includes the fusion partner. This step extracts only the target protein residues.
Step 10 — Validate sequences against UniProt reference
Cross-check all extracted sequences against UniProt reference:
- AlphaFold sequences should be 100% identical to UniProt
- PDB target residues should match the corresponding UniProt region exactly
- Report any mismatches (may indicate mutations, engineered constructs, or parsing errors)
Step 11 — Generate UniProt Excel ({GENE}_Human_Mouse_Uniport.xlsx)
Single-sheet Excel with all UniProt entries, sequences, and cross-references. Color scheme: deep blue header, light blue data rows.
Step 12 — Generate comprehensive Excel ({GENE}_Human_Mouse_Uniport_PDB_AlphaFold.xlsx)
Four-sheet Excel:
- Sheet 1: UniProt sequences (light blue)
- Sheet 2: PDB sequences — chimera rows highlighted orange, non-chimera green
- Sheet 3: AlphaFold sequences (light yellow)
- Sheet 4: Sequence summary — all sources in one table
Step 13 — Generate Markdown report
Comprehensive {GENE}_Human_Mouse_Data_Report.md with:
- Data collection overview table
- UniProt entries table with links
- PDB structures table (method, resolution, chimera status, coverage)
- AlphaFold table (pLDDT scores, model version)
- Sequence summary table (all sources)
- Output files listing
- Data retrieval methods (API endpoints)
- Scientific caveats and limitations
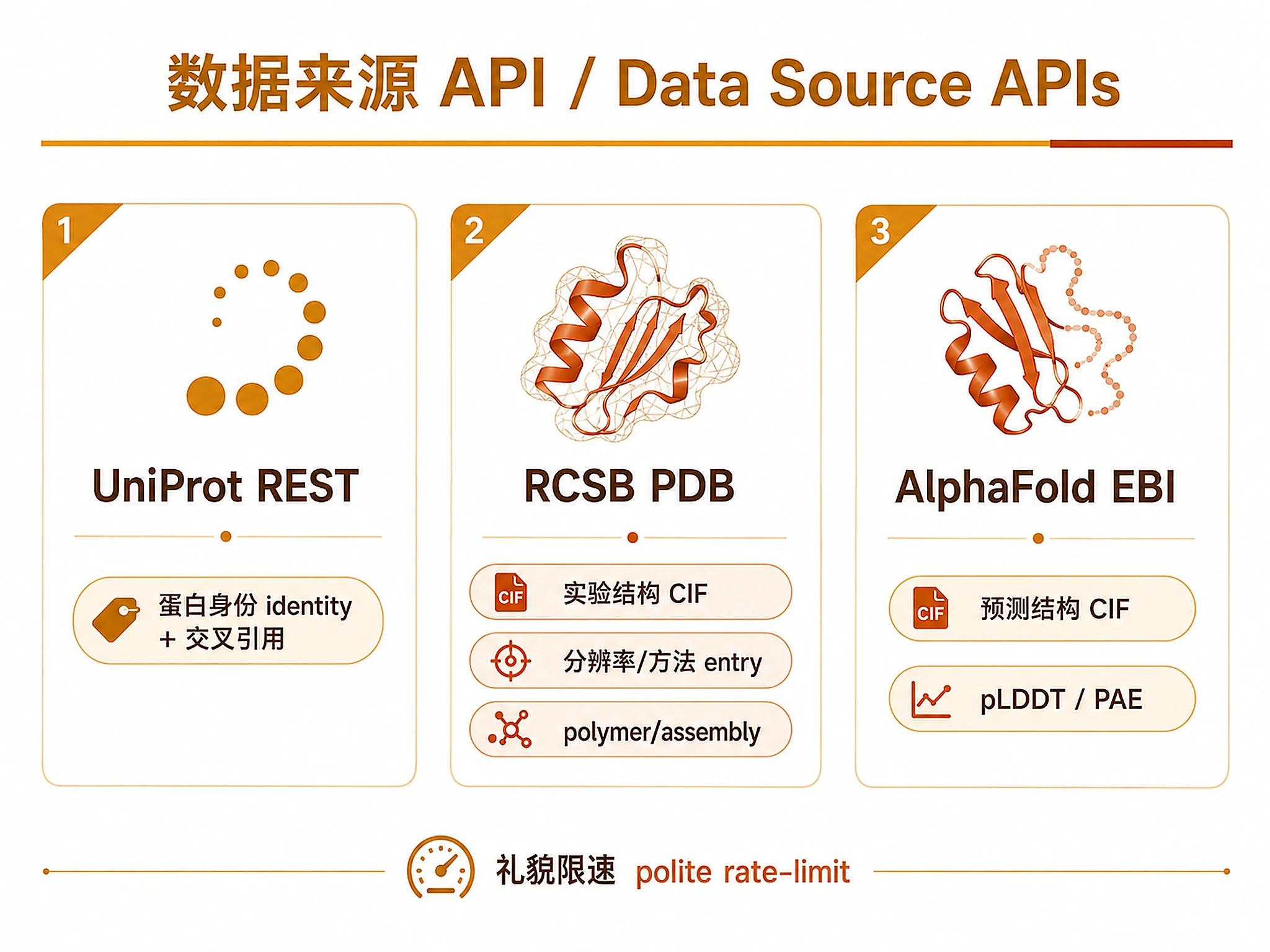
APIs Used
| Database | Endpoint | Auth | Rate limit |
|---|---|---|---|
| UniProt REST | https://rest.uniprot.org/uniprotkb/search |
None | Polite: 0.3s between requests |
| RCSB PDB CIF | https://files.rcsb.org/download/{ID}.cif |
None | Polite: 0.3s |
| RCSB PDB Data | https://data.rcsb.org/rest/v1/core/ |
None | Polite: 0.15s |
| AlphaFold API | https://alphafold.ebi.ac.uk/api/prediction/{acc} |
None | Polite: 0.3s |
| AlphaFold CIF | URL from API cifUrl field |
None | Polite: 0.3s |
Scientific Caveats
-
Chimeric PDB structures: X-ray crystal structures of membrane proteins (especially GPCRs) frequently use fusion proteins inserted into intracellular loops (ICL2, ICL3) to improve crystal contacts. The
polymer_entityJSON and full chain CIF sequence include the fusion partner. The ExcelTarget_Protein_Seq_From_CIFcolumn contains only the target protein residues after removing the fusion partner. -
C-terminal disordered regions: PDB structures often lack C-terminal residues that are disordered in solution. Only AlphaFold provides full-length predictions (with lower pLDDT confidence in disordered regions).
-
AlphaFold model version: The AlphaFold database is updated periodically (v1→v2→v3→v4→v6). Always resolve the current version via the API. As of 2025-05-11, the current version is v6.
-
Redundant UniProt entries: TrEMBL (unreviewed) entries may have identical sequences to Swiss-Prot (reviewed) entries. For most analyses, prefer the reviewed Swiss-Prot entry.
-
PDB DOI fields:
rcsb_primary_citation.pdbx_database_id_doimay be empty in the RCSB API response. Usepdbx_database_id_pub_med(PubMed ID) to retrieve the original publication. -
AlphaMissense annotations: Only available for reviewed Swiss-Prot entries. Unreviewed TrEMBL entries will have
nullforamAnnotationsUrl. -
Polymer entity index: This workflow fetches polymer entity index 1 (
/polymer_entity/{ID}/1). For structures with multiple polymer entities (e.g., receptor + G protein complex), additional entities (index 2, 3, ...) are not fetched. Checkrcsb_entry_container_identifiers.polymer_entity_idsin the entry JSON to see all entity IDs.
Reproducible Notebook
The skill includes notebook_template.ipynb — a fully parameterized Jupyter notebook that
implements all steps above. To use for a new protein:
- Open
notebook_template.ipynb - In Cell 2 (Configuration), set:
python PROTEIN_GENE_NAME = "YOUR_GENE" # e.g., "ADORA2A" OUTPUT_DIR = "./output" - Run all cells (Kernel → Restart & Run All)
Dependencies: requests, pandas, openpyxl, biopython
pip install requests pandas openpyxl biopython
Example Trigger Prompts
- "Collect all human and mouse UniProt, PDB, and AlphaFold data for ADORA2A"
- "Download all CIF structure files for DRD2 in human and mouse"
- "Give me a comprehensive Excel with sequences for HTR2A from UniProt, PDB, and AlphaFold"
- "Get all structural information for the dopamine D2 receptor in human and mouse"
- "I need the PDB and AlphaFold JSON metadata for CHRM1"
Code preview
No Python/R preview files were found.
Companion files
| Type | Path | Bytes |
|---|---|---|
| HTML | notebook_template.ipynb.html | 40,666 |
| Markdown | SKILL.md | 12,122 |
| JSON | skill.meta.json | 1,406 |