Preclinical Literature Mining
Find preclinical studies and extract structured in vitro / in vivo details.
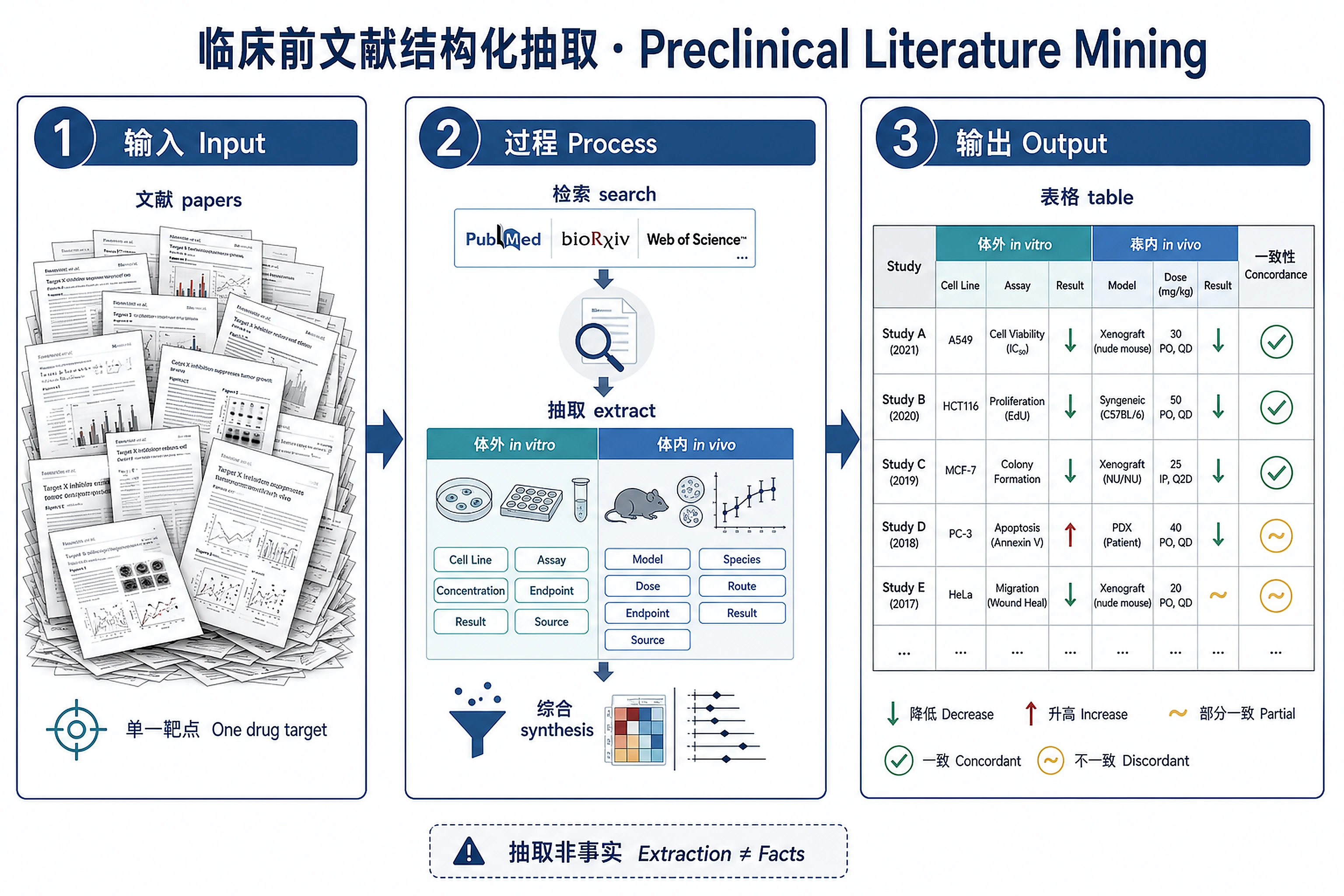
Overview
Problem. Evidence is scattered across more papers than anyone can read.
Learning goals
- Structured extraction turns abstracts into tables
- Watch in vitro vs in vivo concordance
Figures
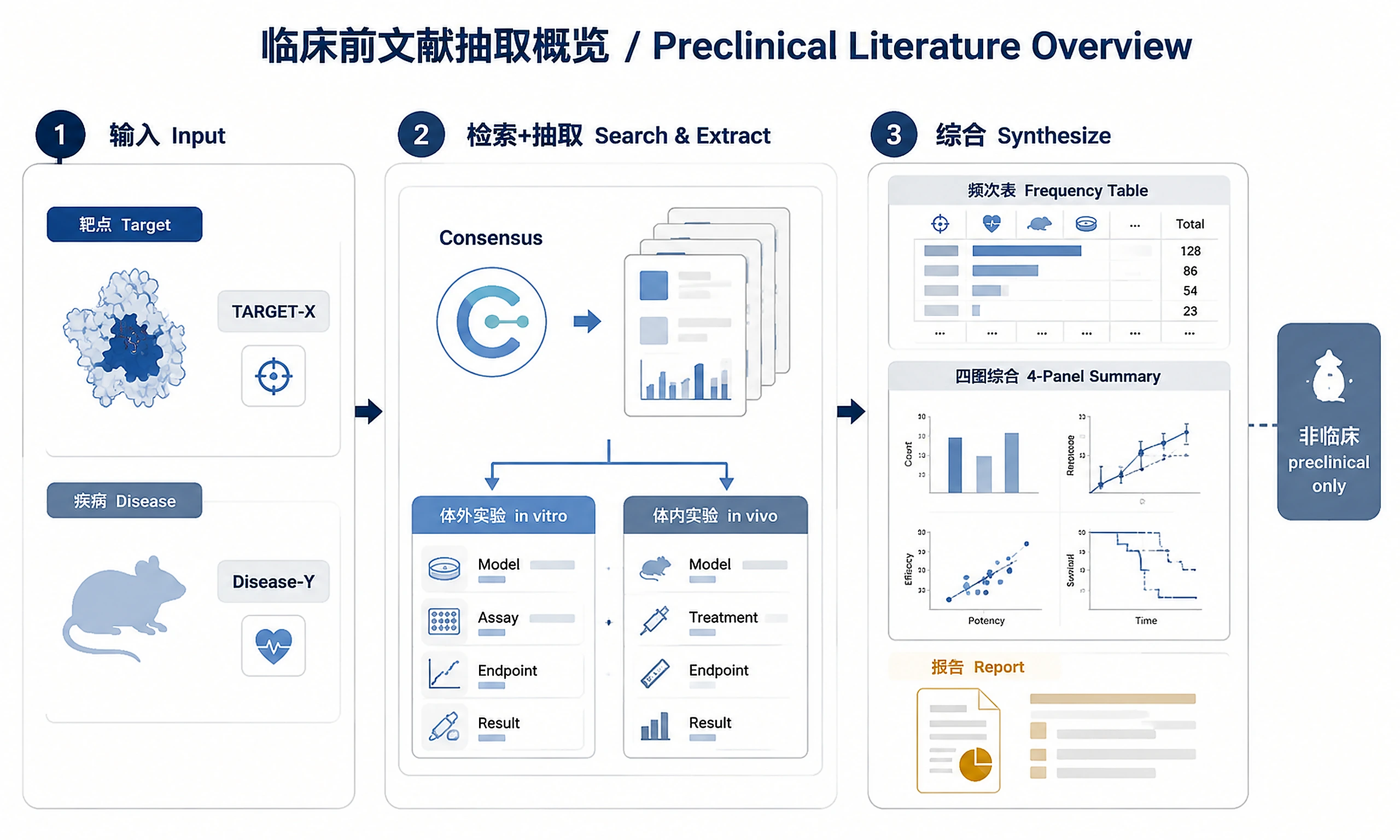
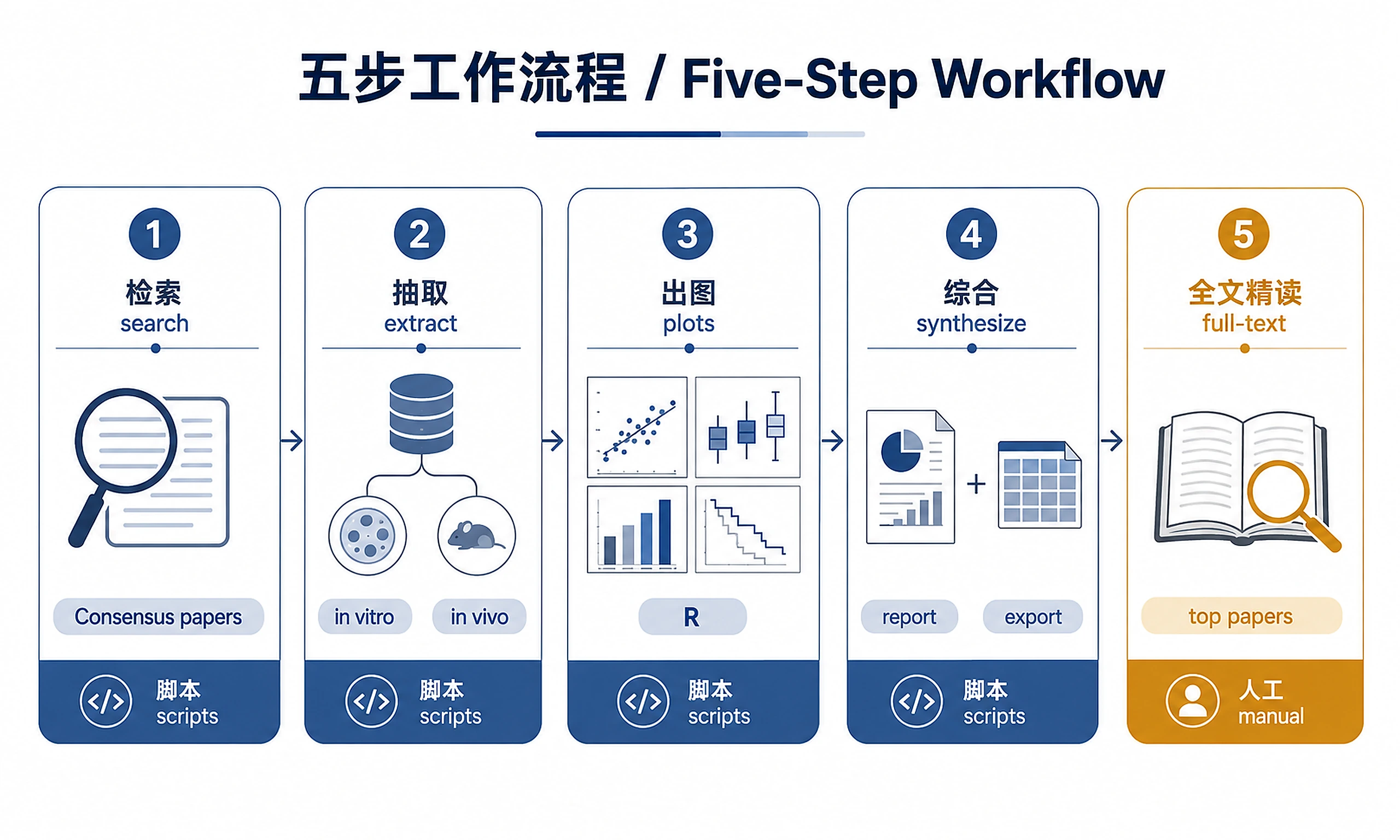
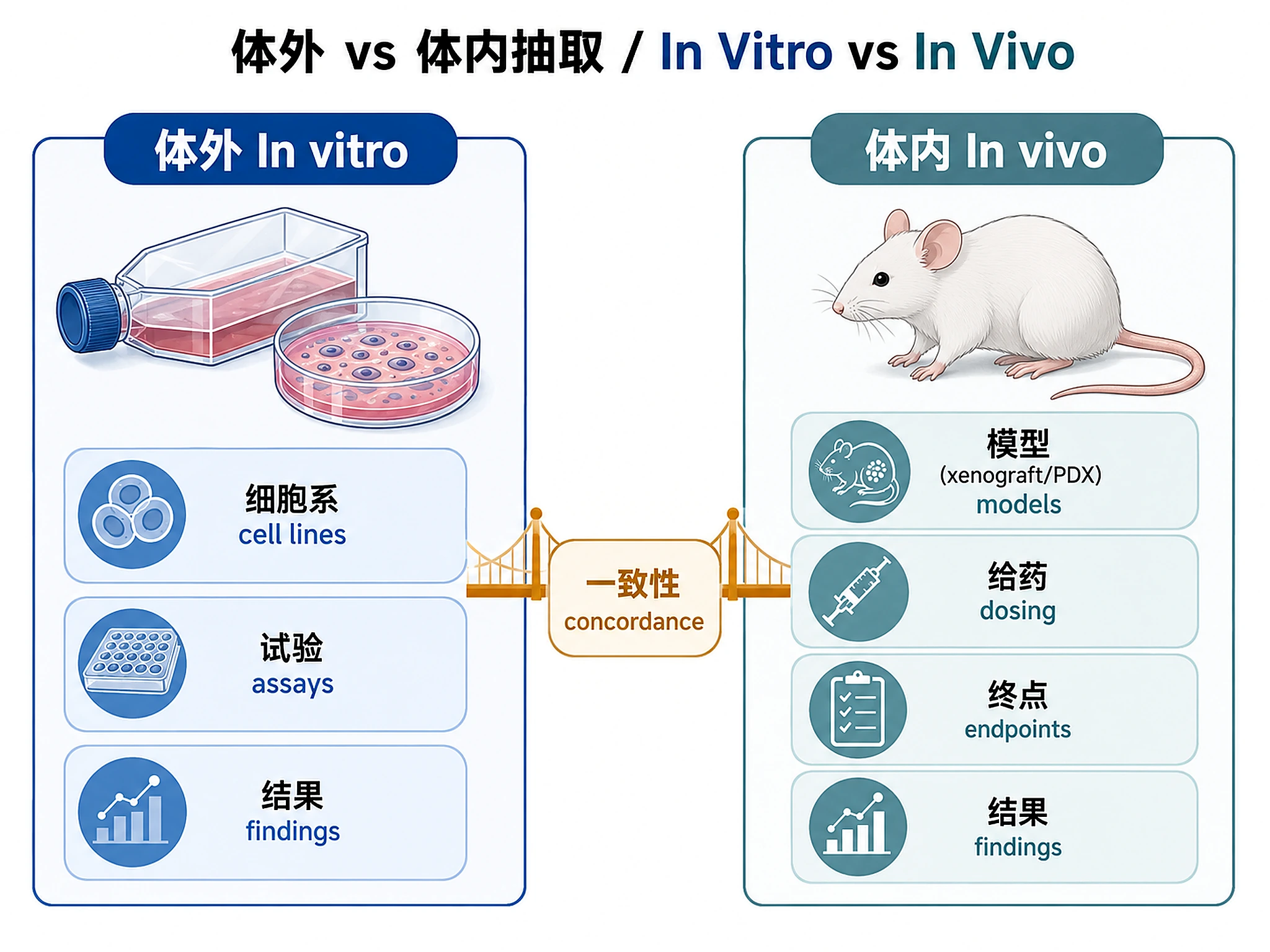

Tutorial
Search Consensus (consensus.app) for preclinical studies on a molecular target in a disease, then extract structured in vitro and in vivo experiment details from each paper.
When to Use This Skill
Use this skill when you need to:
- Survey preclinical evidence for a drug target in a disease indication
- Extract in vitro experiments — cell lines, assays (viability, migration, apoptosis, etc.), key findings
- Extract in vivo experiments — animal models (xenograft, PDX, syngeneic, transgenic), endpoints, key findings
- Identify common model systems — which cell lines and animal models are most used for your target
- Compare in vitro vs in vivo concordance — papers reporting both experiment types
- Support IND-enabling decisions — compile preclinical evidence landscape
Do NOT use this skill for:
- ❌ Clinical trial literature (use
literature-reviewinstead) - ❌ Automated full-text parsing (agent reads full text for top papers after abstract extraction)
- ❌ Meta-analysis or statistical pooling of preclinical results
- ❌ Citation management / formatting only
Installation
Python (Search + Extraction)
pip install requests pandas
PDF Report Generation (Optional)
pip install reportlab
R (Visualization)
install.packages(c("ggplot2", "ggprism", "dplyr", "tidyr", "patchwork"))
# Optional for high-quality SVG:
install.packages("svglite")
Package Licenses
| Software | Version | License | Commercial Use | Installation |
|---|---|---|---|---|
| requests | ≥2.25 | Apache 2.0 | ✅ Permitted | pip install requests |
| pandas | ≥1.3 | BSD | ✅ Permitted | pip install pandas |
| reportlab | ≥3.6 | BSD | ✅ Permitted | pip install reportlab |
| ggplot2 | ≥3.4 | MIT | ✅ Permitted | install.packages("ggplot2") |
| ggprism | ≥1.0.3 | GPL (≥3) | ✅ Permitted | install.packages("ggprism") |
| dplyr | ≥1.1 | MIT | ✅ Permitted | install.packages("dplyr") |
| tidyr | ≥1.3 | MIT | ✅ Permitted | install.packages("tidyr") |
| patchwork | ≥1.1 | MIT | ✅ Permitted | install.packages("patchwork") |
API Requirements:
- Consensus API: Requires
CONSENSUS_API_KEYenvironment variable. Get a key at https://consensus.app/home/api/bash export CONSENSUS_API_KEY="your_key_here"
Inputs
Required Inputs
- Target — Molecular target name (e.g.,
"CDK4/6","BRAF","PD-L1","HER2") - Disease — Disease context (e.g.,
"breast cancer","melanoma","NSCLC")
Optional Inputs
- max_results — Maximum papers to retrieve (default: 50, API max per query: 50)
- years — Search last N years (default: 5)
Outputs
Generated Files
| File | Description |
|---|---|
preclinical_search_results.csv |
All papers with metadata (PMID, DOI, title, abstract, etc.) |
experiment_extraction.csv |
Per-paper extraction: experiment type, cell lines, assays, models, endpoints, findings |
preclinical_synthesis_report.md |
Structured markdown report with narrative synthesis, frequency tables, hyperlinked references, and full-text insights |
preclinical_synthesis_report.pdf |
Publication-quality PDF with Introduction, Methods, Results, Conclusions |
preclinical_plots.png |
4-panel visualization (300 DPI) |
preclinical_plots.svg |
Vector format (with graceful fallback) |
analysis_object.pkl |
Complete analysis object for downstream use |
Analysis object (pickle):
analysis_object.pkl— Contains search results, experiments, synthesis- Load with:
import pickle; obj = pickle.load(open('analysis_object.pkl', 'rb'))
Clarification Questions
🚨 ALWAYS ask Question 1 FIRST.
1. Target and Disease (ASK THIS FIRST):
- Do you have a specific target and disease to search?
- If so: provide the target name and disease
- Or use an example search to try the skill?
- a) CDK4/6 in triple-negative breast cancer
- b) KRAS in pancreatic cancer
- c) PD-L1 in non-small cell lung cancer
- d) BRAF in melanoma
🚨 IF EXAMPLE SEARCH SELECTED: All parameters are pre-defined (last 5 years, 50 results). DO NOT ask questions 2-3. Proceed directly to Step 1.
Questions 2-3 are ONLY for users providing their own target/disease:
2. Search Parameters:
- Date range? (default: last 5 years)
- a) Last 3 years
- b) Last 5 years (default)
- c) Last 10 years
3. Results Scope:
- Maximum papers to retrieve?
- a) 20 (quick scan)
- b) 50 (standard, default)
4. Full-Text Depth:
- How many papers should be reviewed in full text?
- a) Up to 30 papers (default — deeper analysis, takes longer)
- b) Up to 10 papers (faster, focuses on highest-impact papers)
- c) All available open-access papers (comprehensive, slowest)
Standard Workflow
🚨 MANDATORY: USE SCRIPTS EXACTLY AS SHOWN - DO NOT WRITE INLINE CODE 🚨
⚠️ CRITICAL - DO NOT:
- ❌ Write inline Consensus/PubMed API code → STOP: Use
search_preclinical() - ❌ Write inline extraction code → STOP: Use
extract_all_experiments() - ❌ Write inline plotting code (ggplot, ggsave, etc.) → STOP: Use
generate_all_plots() - ❌ Write custom export code → STOP: Use
export_all() - ❌ Try to install svglite → script handles SVG fallback automatically
Steps 1-4 are automated (scripts). Step 5 is agent-guided (manual full-text reading).
Step 1 — Search for preclinical studies:
import sys
sys.path.append("scripts")
from preclinical_search import search_preclinical
results = search_preclinical(
target="CDK4/6",
disease="triple-negative breast cancer",
max_results=50,
years=5,
output_dir="preclinical_results"
)
DO NOT write inline Consensus API code. Use the script.
Step 2 — Extract in vitro and in vivo experiments:
from extract_experiments import extract_all_experiments
experiments = extract_all_experiments(results, output_dir="preclinical_results")
DO NOT write inline extraction code. The script handles all keyword matching.
Step 3 — Generate visualizations:
source("scripts/generate_plots.R")
generate_all_plots(input_dir = "preclinical_results", output_dir = "preclinical_results")
DO NOT write inline plotting code (ggplot, ggsave, etc.). Just source the script.
The script handles PNG + SVG export with graceful fallback for SVG dependencies.
Step 4 — Synthesize and export results:
from preclinical_synthesis import synthesize_preclinical, export_all
synthesis = synthesize_preclinical(results, experiments, target="CDK4/6")
export_all(results, experiments, synthesis,
target="CDK4/6", disease="triple-negative breast cancer",
output_dir="preclinical_results")
DO NOT write custom export code. Use export_all().
Step 5 — Full-text deep dive (top papers):
Read the full-text enrichment guide and follow its instructions to read full text for the top papers (default: up to 30). Replace the ## Full-Text Insights placeholder in the report with per-paper findings.
DO NOT skip this step. Select papers based on the criteria in the guide.
✅ VERIFICATION — You should see:
- After Step 1:
"✓ Literature search completed successfully!" - After Step 2:
"✓ Experiment extraction completed successfully!" - After Step 3:
"✓ All plots generated successfully!" - After Step 4:
"=== Export Complete ===" - After Step 5: Report contains
## Full-Text Insightssection with per-paper details
❌ IF YOU DON'T SEE THESE: You wrote inline code. Stop and use the scripts.
Common Issues
| Issue | Cause | Solution |
|---|---|---|
| "CONSENSUS_API_KEY not set" | API key missing | export CONSENSUS_API_KEY='your_key_here' — get key at https://consensus.app/home/api/ |
| "Invalid or expired API key" | Bad API key | Verify your CONSENSUS_API_KEY is valid and not expired |
| "HTTP 429: Rate limited" | Consensus rate limit exceeded | Script handles retries with exponential backoff. Wait and retry if persists |
| "No results found" | Query too specific or target name mismatch | Try alternative target names (e.g., "CDK4" vs "CDK4/6" vs "cyclin-dependent kinase 4") |
| "experiment_extraction.csv not found" | Step 2 not run before Step 3 | Run Steps 1-2 (Python) before Step 3 (R) |
| "Most papers classified as unclassified" | Abstracts don't contain expected keywords | Expected for some targets — check if papers use different terminology |
| "Missing R package: ggprism" | R packages not installed | install.packages(c("ggplot2", "ggprism", "dplyr", "tidyr", "patchwork")) |
| SVG export failed | Missing svglite dependency | Normal — script falls back to base R svg() device. PNG always generated |
| "PDF skipped" | Missing reportlab package | pip install reportlab. Markdown report always generated regardless |
⚠️ IF SCRIPTS FAIL — Script Failure Hierarchy:
- Fix and Retry (90%) — Install missing package, re-run script
- Modify Script (5%) — Edit the script file itself, document changes
- Use as Reference (4%) — Read script, adapt approach, cite source
- Write from Scratch (1%) — Only if genuinely impossible, explain why
NEVER skip directly to writing inline code without trying the script first.
Suggested Next Steps
After extracting preclinical experiments:
- Deep dive — Read full-text papers for the most relevant "both" papers (in vitro + in vivo)
- Expand search — Try alternative target names or broader disease terms
- Functional enrichment — Use
functional-enrichment-from-degson genes from relevant pathways - Literature review — Use
literature-reviewfor broader context including clinical studies - Target gene analysis — Use
chip-atlas-target-genesto identify transcription factor targets
Related Skills
Upstream Skills
- literature-review — General literature search and synthesis (broader scope)
Downstream Skills
- functional-enrichment-from-degs — Pathway analysis of target-related genes
- chip-atlas-target-genes — Identify TF binding targets for your target gene
- chip-atlas-peak-enrichment — Check ChIP-seq enrichment near your target
References
Search Strategy
- [references/preclinical-search-guide.md] — Consensus API search strategies, query construction, API parameters
Extraction Methods
- [references/experiment-extraction-guide.md] — Keyword-based extraction approach, dictionaries, limitations
External Documentation
- Consensus API: https://consensus.app/home/api/
Code preview
assets/eval/simple_test.py
#!/usr/bin/env python3
"""
Simple test for literature-preclinical skill.
Mock test: Validates experiment extraction logic (Steps 2-4) without network.
Live test: Full Consensus search + extraction (requires network + CONSENSUS_API_KEY).
Usage:
python3 simple_test.py # Mock test only
python3 simple_test.py --live # Mock + live test (needs CONSENSUS_API_KEY)
"""
import os
import sys
import json
import shutil
# Add scripts/ to path
SCRIPT_DIR = os.path.dirname(os.path.abspath(__file__))
SKILL_DIR = os.path.join(SCRIPT_DIR, "..", "..")
sys.path.insert(0, os.path.join(SKILL_DIR, "scripts"))
TEST_OUTPUT_DIR = os.path.join(SCRIPT_DIR, "test_results")
# ---------------------------------------------------------------------------
# Mock abstracts with known in vitro / in vivo content
# ---------------------------------------------------------------------------
MOCK_PAPERS = [
{
"pmid": "MOCK001",
"doi": "10.1234/mock001",
"title": "CDK4/6 inhibition suppresses triple-negative breast cancer cell proliferation in vitro and in vivo",
"authors": "Smith J, Jones A, Wang L et al.",
"journal": "Cancer Research (2024)",
"publication_date": "2024-03-15",
"abstract": (
"CDK4/6 inhibitors have shown promise in hormone receptor-positive breast cancer, "
"but their role in triple-negative breast cancer (TNBC) remains unclear. "
"We investigated the effects of palbociclib on TNBC cell lines in vitro and in vivo. "
"MDA-MB-231 and BT-549 cells were treated with palbociclib. Cell viability was assessed "
"by MTT assay, and apoptosis was measured by annexin V/PI staining and flow cytometry. "
"Western blot analysis showed reduced phosphorylation of Rb protein. "
"Colony formation assays demonstrated significantly reduced proliferation. "
"In a subcutaneous xenograft model using nude mice, palbociclib significantly inhibited "
"tumor growth compared to vehicle control. Tumor volume was reduced by 65% at day 28. "
"Immunohistochemistry of tumor sections showed decreased Ki-67 staining. "
"Body weight monitoring showed no significant toxicity."
),
"keywords": "CDK4/6; breast cancer; palbociclib; xenograft",
"url": "https://pubmed.ncbi.nlm.nih.gov/MOCK001/",
"source": "PubMed",
},
{
"pmid": "MOCK002",
"doi": "10.1234/mock002",
"title": "KRAS G12C inhibitor demonstrates anti-tumor activity in pancreatic cancer cell lines",
"authors": "Chen X, Kim Y, Park S",
"journal": "Molecular Cancer Therapeutics (2023)",
"publication_date": "2023-11-01",
"abstract": (
"KRAS G12C mutations are found in a subset of pancreatic cancers. "
"We evaluated a novel KRAS G12C inhibitor in pancreatic cancer cell lines. "
"PANC-1 and MiaPaCa-2 cells were treated with increasing doses of the inhibitor. "
"CCK-8 assay showed dose-dependent reduction in cell viability with IC50 values "
"of 2.3 uM and 4.1 uM respectively. Transwell migration assay revealed significantly "
"reduced invasion capacity. qPCR analysis demonstrated downregulation of MYC and "
"ERK pathway genes. Caspase-3/7 activity was significantly increased, indicating "
"apoptosis induction."
),
"keywords": "KRAS; pancreatic cancer; targeted therapy",
"url": "https://pubmed.ncbi.nlm.nih.gov/MOCK002/",
"source": "PubMed",
},
{
"pmid": "MOCK003",
"doi": "10.1234/mock003",
"title": "PD-L1 blockade enhances anti-tumor immunity in syngeneic mouse models of NSCLC",
"authors": "Rodriguez M, Taylor B, Wilson K",scripts/extract_experiments.py
"""
Preclinical Experiment Extraction Module
Parse abstracts to extract structured in vitro and in vivo experiment details.
Uses keyword-based extraction to identify cell lines, assays, animal models,
endpoints, and key findings from each paper.
"""
import re
import os
from typing import List, Dict, Tuple
import pandas as pd
# ---------------------------------------------------------------------------
# Keyword dictionaries
# ---------------------------------------------------------------------------
# In vitro indicators
IN_VITRO_KEYWORDS = [
"cell line", "cell lines", "cell culture", "in vitro", "cultured cells",
"transfect", "transduct", "knockdown", "overexpress", "overexpression",
"siRNA", "shRNA", "CRISPR", "sgRNA",
"co-culture", "monolayer", "spheroid", "organoid",
]
# Common cell line names (case-insensitive matching handled separately)
CELL_LINE_NAMES = [
"MCF-7", "MCF7", "MDA-MB-231", "MDA-MB-468", "T47D", "BT-474", "BT474",
"BT-549", "BT549", "MDA-MB-453", "CAL-51", "HCC1937", "HCC1806",
"SK-BR-3", "SKBR3", "ZR-75", "4T1", "EMT6",
"HeLa", "HEK293", "HEK-293", "293T", "HEK293T",
"A549", "H1299", "H460", "H1975", "PC9", "HCC827",
"HCT116", "HT29", "SW480", "SW620", "LoVo", "Caco-2",
"U87", "U251", "T98G", "LN229",
"PC3", "PC-3", "LNCaP", "DU145", "22Rv1", "VCaP",
"K562", "HL60", "HL-60", "Jurkat", "THP-1", "U937",
"HepG2", "Hep3B", "Huh7", "SMMC-7721",
"PANC-1", "MiaPaCa-2", "BxPC-3", "AsPC-1",
"A375", "SK-MEL-28", "B16", "B16F10",
"OVCAR3", "SKOV3", "A2780",
"CHO", "NIH3T3", "3T3", "COS-7",
"Raji", "Ramos", "Daudi",
"SH-SY5Y", "Neuro-2a", "N2a",
"RAW264.7", "RAW 264.7", "J774",
]
# Assay keyword categories
ASSAY_KEYWORDS = {
"viability": [
"viability", "MTT", "CCK-8", "CCK8", "WST", "cell counting",
"CellTiter", "MTS", "XTT", "alamarBlue", "resazurin",
"cytotoxicity", "IC50", "EC50", "dose-response",
],
"proliferation": [
"proliferation", "colony formation", "clonogenic", "BrdU", "EdU",
"Ki-67", "Ki67", "cell growth", "growth curve", "doubling time",
],
"apoptosis": [
"apoptosis", "annexin", "caspase", "TUNEL", "cell death",
"sub-G1", "programmed cell death", "Bcl-2", "BAX",
"cleaved PARP", "cytochrome c release",
],
"migration_invasion": [
"migration", "invasion", "wound healing", "transwell", "Boyden",
"scratch assay", "chemotaxis", "Matrigel",
],
"gene_expression": [
"qPCR", "RT-PCR", "real-time PCR", "qRT-PCR",
"mRNA expression", "RNA-seq", "RNAseq", "transcriptom",
"gene expression", "Northern blot",
],
"protein_analysis": [
"Western blot", "immunoblot", "ELISA", "immunoprecipitation",
"phosphorylation", "Co-IP", "pull-down", "mass spectrometry",
"proteomics", "immunofluorescence",
],
"flow_cytometry": [
"flow cytometry", "FACS", "cell cycle", "cell sorting",
"intracellular staining", "surface marker",scripts/generate_plots.R
#!/usr/bin/env Rscript
#
# Generate 4-panel preclinical experiment visualization (Step 3).
#
# Creates:
# 1. Experiment type breakdown (in vitro / in vivo / both / unclassified)
# 2. Top assay types (horizontal bar chart)
# 3. Animal model distribution (bar chart)
# 4. Publication timeline by experiment type (stacked bars)
#
# Uses ggplot2 with ggprism publication theme.
# Exports both PNG (300 DPI) and SVG with graceful fallback.
#
# --- Load packages -----------------------------------------------------------
required_pkgs <- c("ggplot2", "ggprism", "dplyr", "tidyr", "patchwork")
for (pkg in required_pkgs) {
if (!requireNamespace(pkg, quietly = TRUE)) {
stop(paste0("Missing required package: ", pkg,
"\nInstall with: install.packages('", pkg, "')"))
}
}
library(ggplot2)
library(ggprism)
library(dplyr)
library(tidyr)
library(patchwork)
# Try to load svglite for high-quality SVG (optional)
.has_svglite <- requireNamespace("svglite", quietly = TRUE)
if (.has_svglite) library(svglite)
# --- Main function -----------------------------------------------------------
generate_all_plots <- function(input_dir = "preclinical_results",
output_dir = "preclinical_results") {
cat("\n", paste(rep("=", 70), collapse = ""), "\n")
cat("GENERATING VISUALIZATIONS\n")
cat(paste(rep("=", 70), collapse = ""), "\n\n")
dir.create(output_dir, showWarnings = FALSE, recursive = TRUE)
# Read extraction CSV
extract_file <- file.path(input_dir, "experiment_extraction.csv")
if (!file.exists(extract_file)) {
stop(paste("File not found:", extract_file,
"\nRun Steps 1-2 first to generate experiment_extraction.csv"))
}
df <- read.csv(extract_file, stringsAsFactors = FALSE)
cat(" Read", nrow(df), "papers from", extract_file, "\n\n")
# Build 4 panels
cat("1. Generating experiment type breakdown...\n")
p1 <- .plot_experiment_types(df)
cat("2. Generating top assay types...\n")
p2 <- .plot_assay_types(df)
cat("3. Generating animal model distribution...\n")
p3 <- .plot_animal_models(df)
cat("4. Generating publication timeline...\n")
p4 <- .plot_timeline(df)
# Combine with patchwork
cat("\n5. Saving combined figure...\n")
combined <- (p1 | p2) / (p3 | p4) +
plot_annotation(
title = "Preclinical Literature Extraction",
subtitle = paste(nrow(df), "papers analyzed"),
theme = theme(
plot.title = element_text(hjust = 0.5, face = "bold", size = 16),
plot.subtitle = element_text(hjust = 0.5, size = 12)
)
)Companion files
| Type | Path | Bytes |
|---|---|---|
| Python | assets/eval/simple_test.py | 17,253 |
| Text | assets/eval/test_results/analysis_object.pkl.UNAVAILABLE.txt | 319 |
| CSV | assets/eval/test_results/experiment_extraction.csv | 2,265 |
| CSV | assets/eval/test_results/preclinical_search_results.csv | 3,593 |
| Markdown | assets/eval/test_results/preclinical_synthesis_report.md | 4,965 |
| Text | assets/eval/test_results/preclinical_synthesis_report.pdf.UNAVAILABLE.txt | 345 |
| Python | scripts/extract_experiments.py | 13,714 |
| R | scripts/generate_plots.R | 9,639 |
| Python | scripts/generate_report.py | 22,210 |
| Python | scripts/narrative_synthesis.py | 24,508 |
| Python | scripts/preclinical_search.py | 9,917 |
| Python | scripts/preclinical_synthesis.py | 8,866 |
| Python | scripts/report_generation.py | 11,998 |
| Markdown | SKILL.md | 10,910 |
| JSON | skill.meta.json | 3,044 |