Open Targets (GraphQL)
Query the Open Targets API for target–disease associations and evidence.
Overview
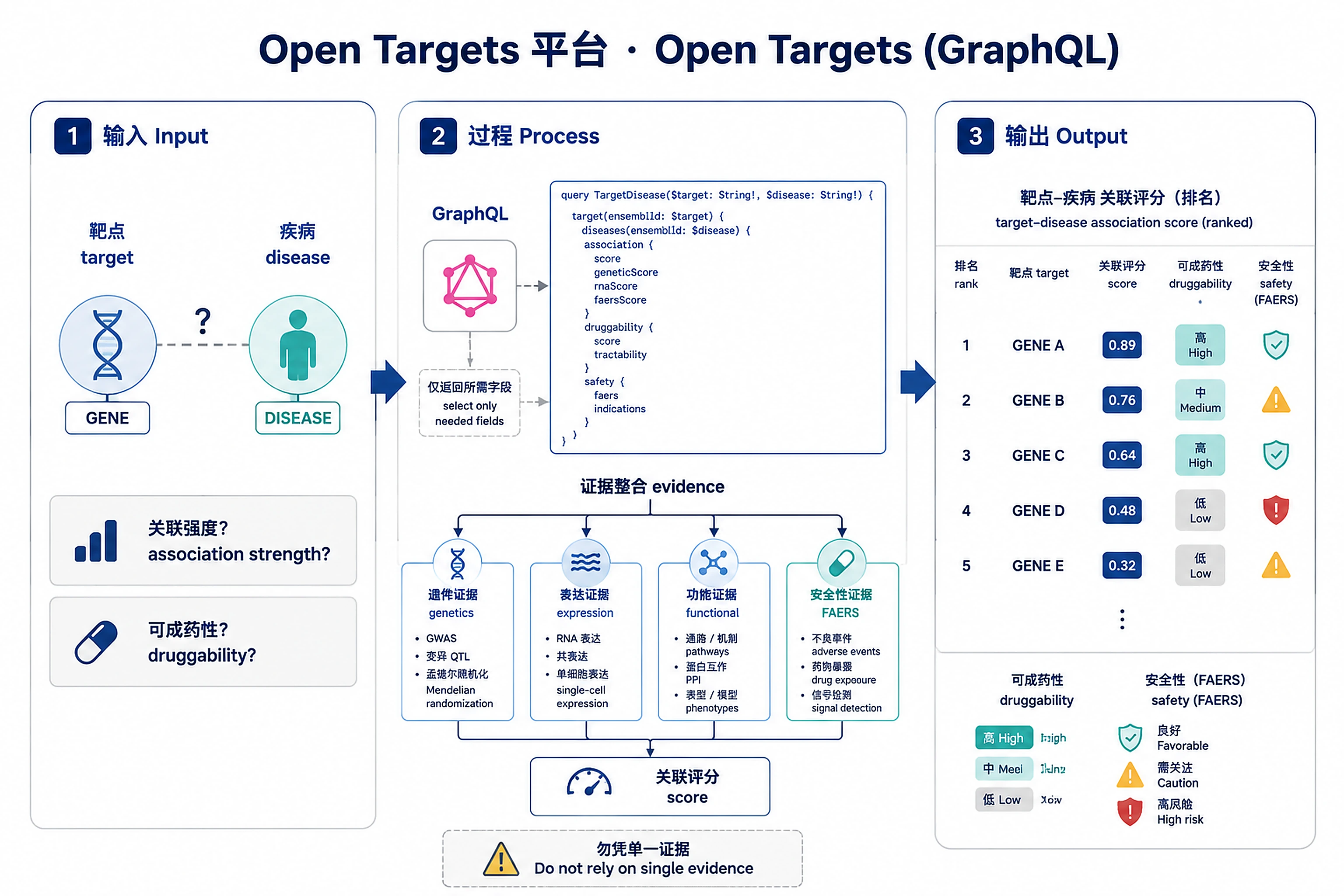
Problem. How strong is the gene–disease link; is it druggable?
Learning goals
- Modern target ID integrates many evidence lines
- GraphQL fetches only the fields you need
Figures
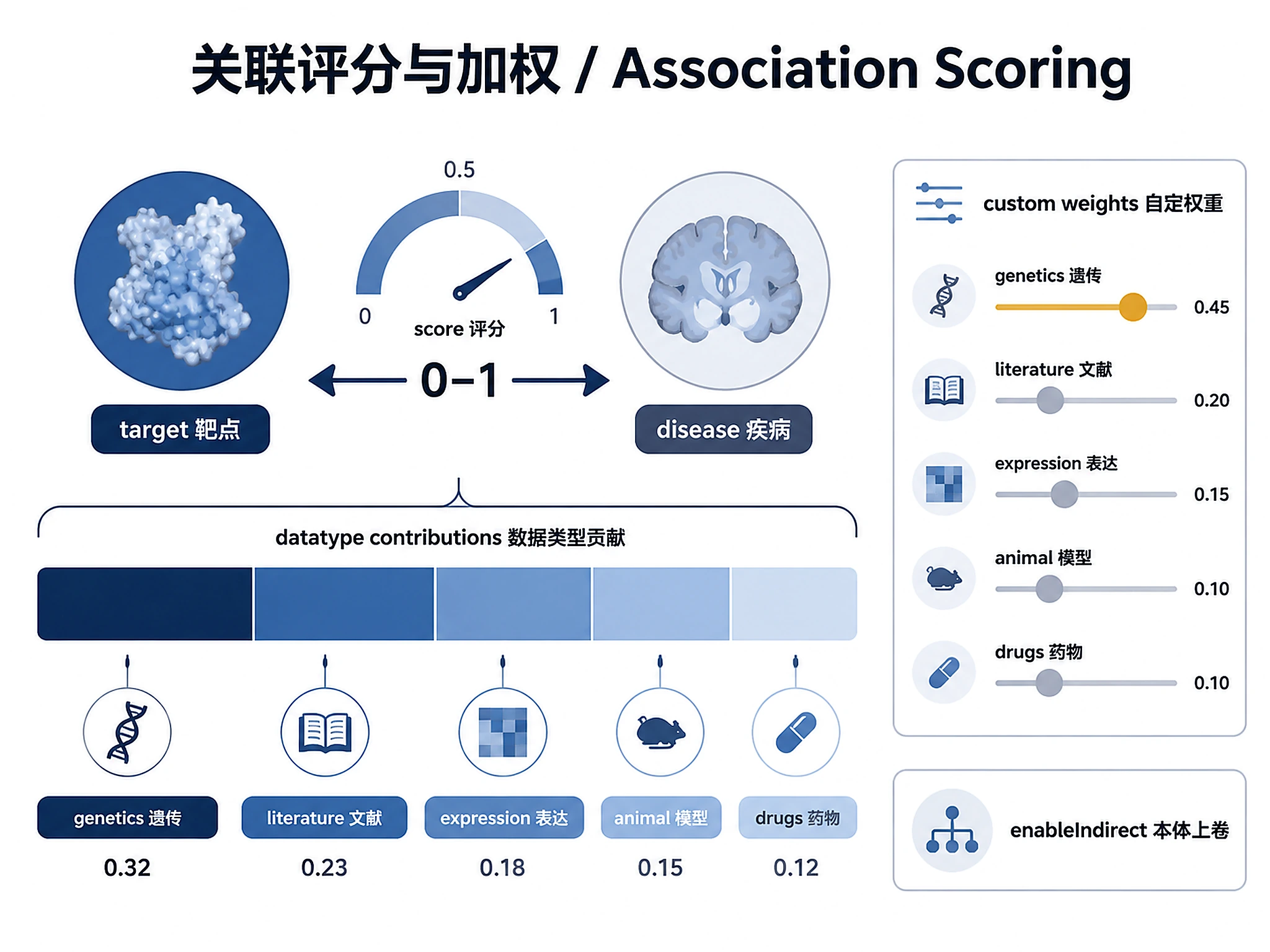

Tutorial
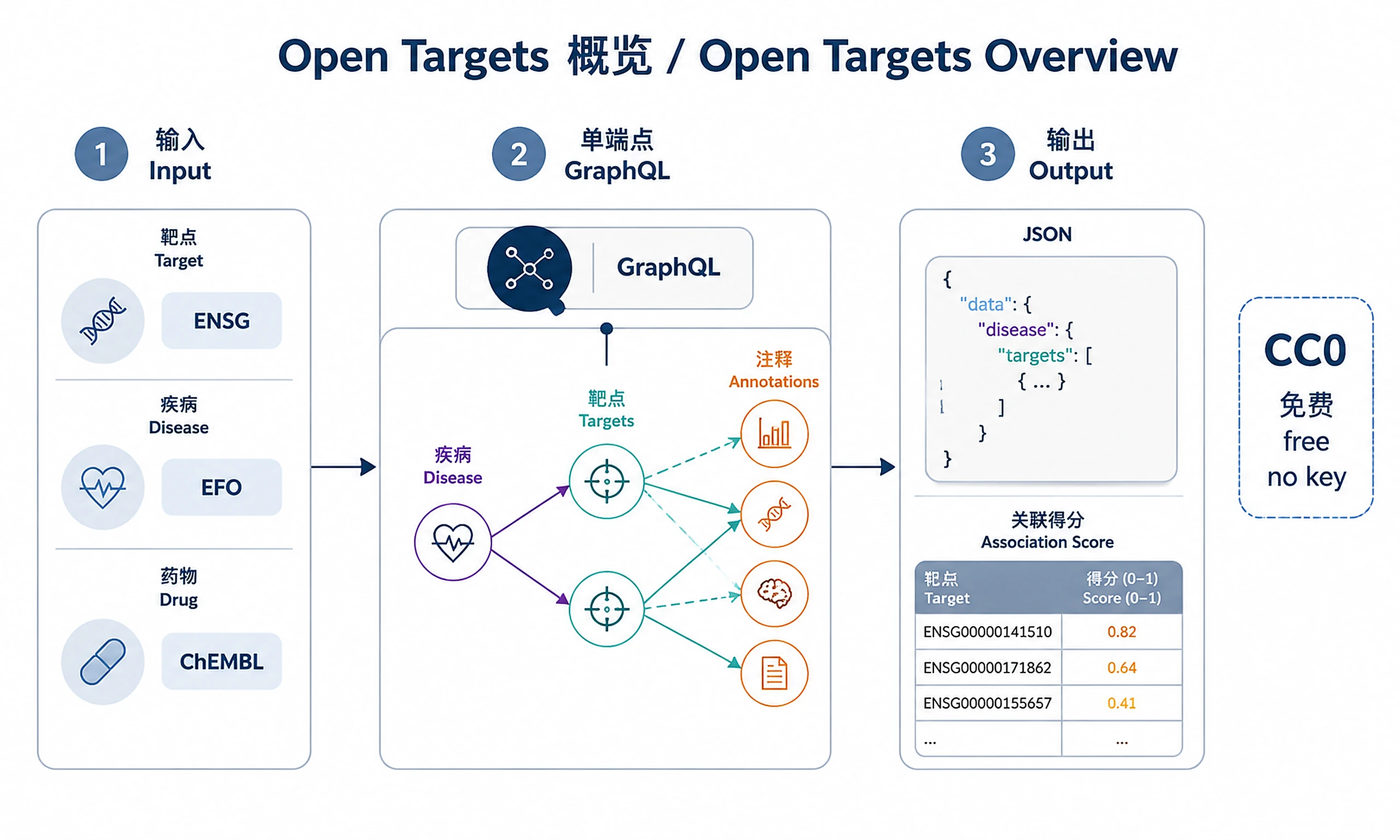
Programmatic access to Open Targets target–disease associations, evidence, and annotations via a single GraphQL endpoint.
When to Use This Skill
Use Open Targets when the user wants:
- ✅ Target annotations (genes/proteins by Ensembl ID): tractability, essentiality, expression, constraint, safety, known drugs
- ✅ Disease annotations (by EFO ID): ontology, known drugs, associated targets, clinical signs
- ✅ Drug/compound info (by ChEMBL ID): mechanism of action, indications, trial phase, pharmacovigilance
- ✅ Target–disease association scores and evidence across 20+ datasources, with optional custom weighting
- ✅ Variants, GWAS studies, credible sets, L2G (former Genetics Portal — now part of the Platform API)
- ✅ Name → ID resolution for genes, diseases, drugs
Don't use Open Targets for:
- ❌ Bulk/systematic extraction across many entities → use the FTP downloads, BigQuery (
open-targets-prod), or AWS Open Data buckets instead - ❌ Non-human biology, general literature search, EHR/clinical-trial-recruitment data, or proprietary datasets
Quick Start
Test this skill in ~30 seconds — no API key required:
import requests
URL = "https://api.platform.opentargets.org/api/v4/graphql"
query = """
query { disease(efoId: "MONDO_0004975") {
name
associatedTargets(page: { index: 0, size: 5 }) {
rows { target { approvedSymbol } score }
}
} }
"""
print(requests.post(URL, json={"query": query}).json())
Expected: Top 5 targets associated with Alzheimer's disease (MONDO_0004975) with overall association scores (0–1).
Installation
Required:
pip install requests
Optional (for tabular handling):
pip install pandas
No API key, no auth, no rate-limit headers in the public docs. The maintainers ask you not to loop one entity at a time — use bulk downloads for that.
License: Open Targets data is released under CC0 1.0; the API is free to use.
Inputs
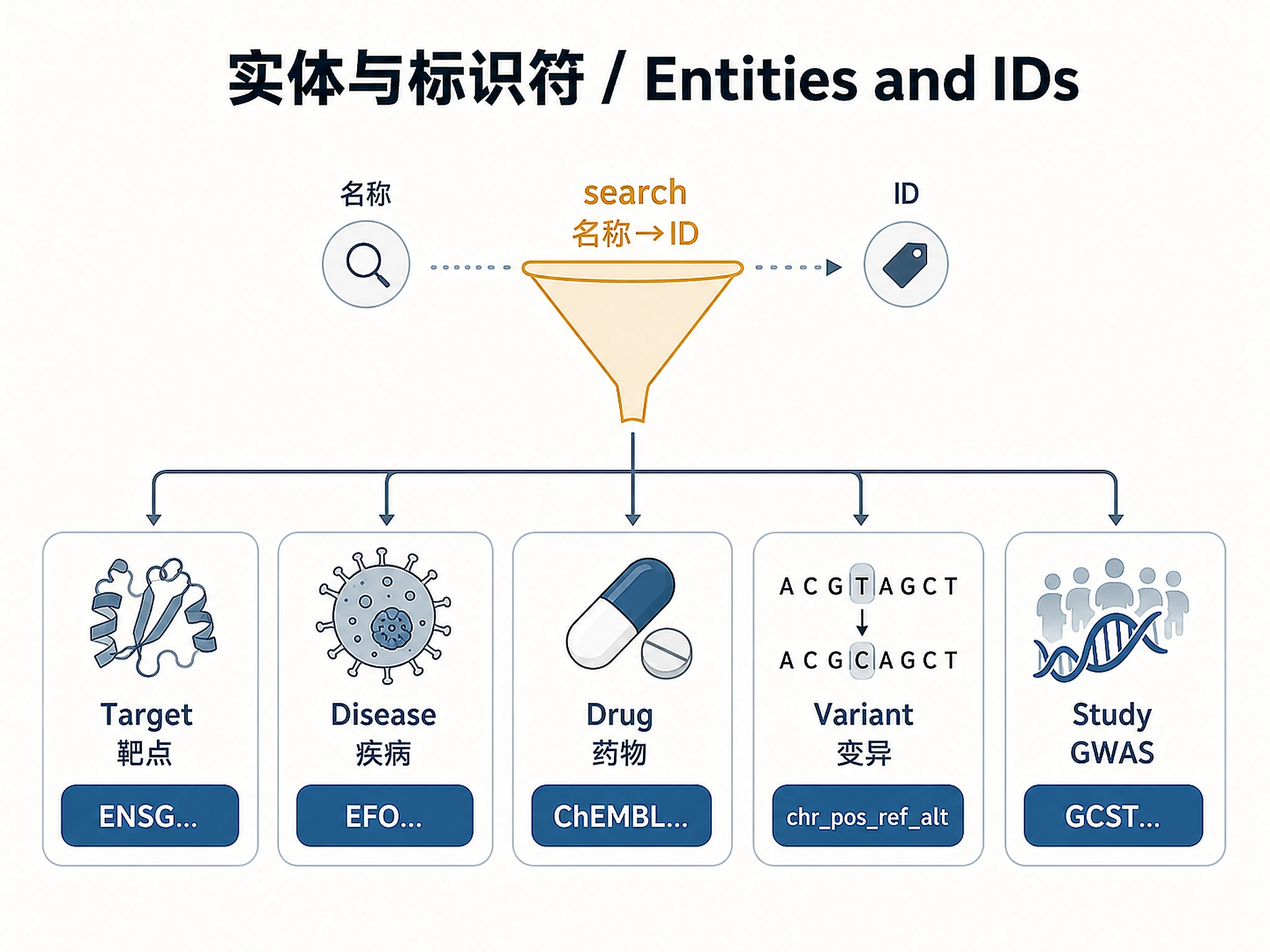
Required for most queries — one of the following standardised IDs:
| Entity | ID format | Example |
|---|---|---|
| Target | Ensembl gene | ENSG00000169083 |
| Disease | EFO (or imported) | MONDO_0004975 |
| Drug | ChEMBL | CHEMBL1201583 |
| Variant | chrom_pos_ref_alt |
19_44908822_C_T |
| Study | GWAS Catalog | GCST005194 |
If the user provides a free-text name or non-primary identifier (gene symbol, disease name, drug brand, HGNC ID), resolve it first with the search query before any other call.
Outputs
GraphQL returns JSON shaped exactly like your query. Typical deliverables for the user:
- Association tables: target ↔ disease with
scoreand per-datatype breakdowns - Evidence rows: individual evidence records (datasource, score, supporting literature/links)
- Annotation summaries: target/disease/drug profile data
- Variant & GWAS data: credible sets, L2G predictions, colocalisation
- Resolved IDs from
searchhits
CSV/TSV export from the JSON is straightforward with pandas.json_normalize.
Clarification Questions
Ask only for missing information. If the user already gave a standard ID and a clear goal, proceed directly.
1. Entity & ID:
- What entity is the question about — target, disease, drug, variant, or study?
- Do you already have an Ensembl/EFO/ChEMBL/GCST ID, or only a name? (If only a name, this skill resolves it via
searchfirst.)
2. Goal: Annotation lookup, target–disease associations, supporting evidence, or genetics (variant/GWAS/L2G)?
3. Scope:
- Single entity? → API is appropriate
- Tens to hundreds across many entities? → still OK with paginated queries
- Thousands or "all targets"? → stop and recommend bulk downloads instead
4. Filters / weighting (associations only): Default scoring, or custom datasource weights (e.g. "genetics-only", "downweight literature")? Roll up evidence through disease ontology descendants (enableIndirect: true)?
5. Output: Print summary, return JSON, or save to CSV/TSV?
Standard Workflow
Endpoint: https://api.platform.opentargets.org/api/v4/graphql
Playground (with built-in schema docs): https://api.platform.opentargets.org/api/v4/graphql/browser
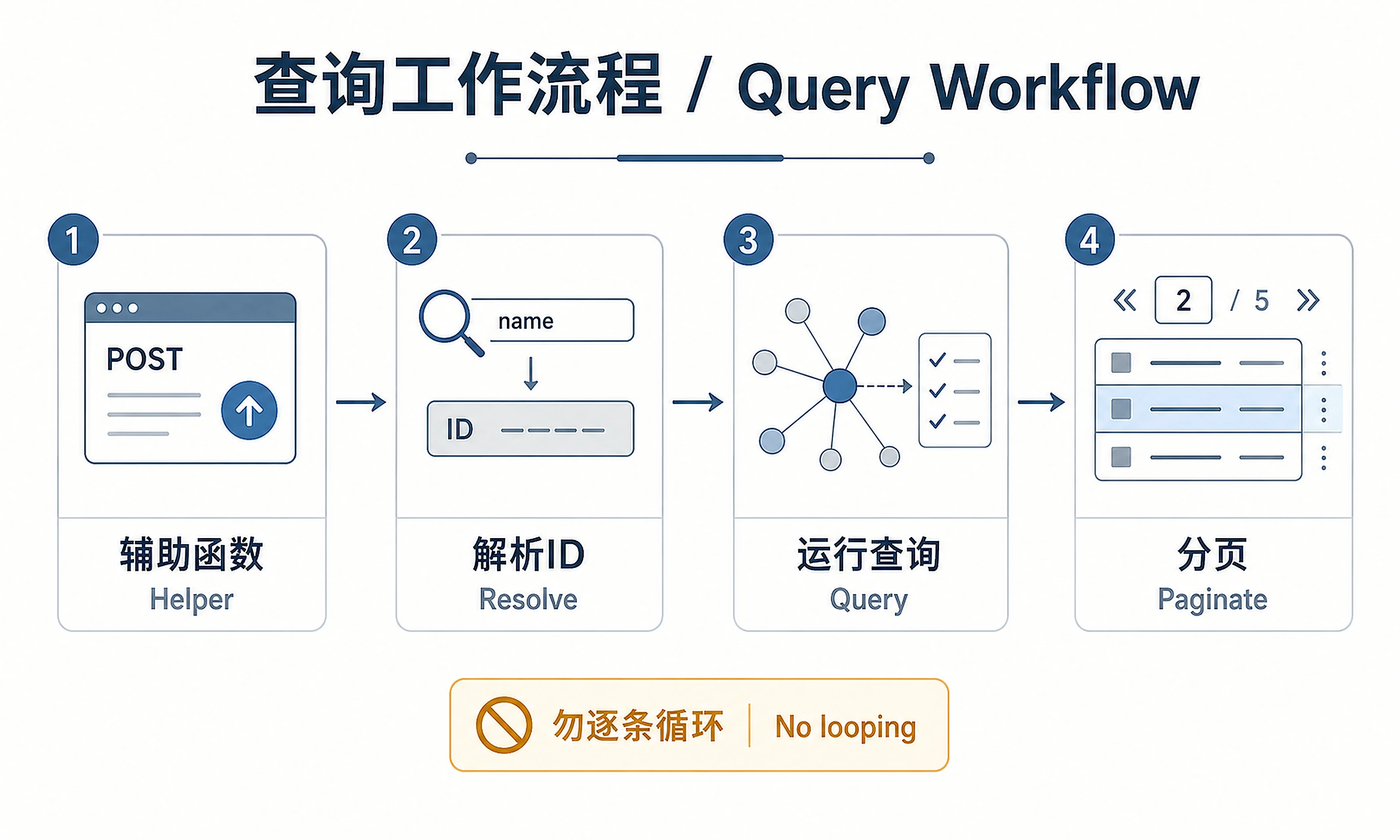
Step 1 — Helper
import requests
URL = "https://api.platform.opentargets.org/api/v4/graphql"
def ot_query(query: str, variables: dict | None = None) -> dict:
r = requests.post(URL, json={"query": query, "variables": variables or {}})
r.raise_for_status()
payload = r.json()
if "errors" in payload:
raise RuntimeError(payload["errors"])
return payload["data"]
Step 2 — Resolve names → IDs (only if needed)
QUERY = """
query Search($q: String!) {
search(queryString: $q, entityNames: ["target","disease","drug"]) {
hits { id name entity }
}
}
"""
ot_query(QUERY, {"q": "BRCA1"})
Step 3 — Run the actual query
Target annotation:
QUERY = """
query Target($ensemblId: String!) {
target(ensemblId: $ensemblId) {
id approvedSymbol biotype
geneticConstraint { constraintType score oe oeLower oeUpper }
tractability { label modality value }
}
}
"""
ot_query(QUERY, {"ensemblId": "ENSG00000169083"}) # AR
Disease → known drugs + top associated targets:
QUERY = """
query Disease($efoId: String!) {
disease(efoId: $efoId) {
id name
knownDrugs { uniqueDrugs rows { drug { id name isApproved } } }
associatedTargets(page: { index: 0, size: 25 }) {
rows {
target { id approvedSymbol }
score
datatypeScores { id score }
}
}
}
}
"""
ot_query(QUERY, {"efoId": "MONDO_0004975"}) # Alzheimer's
Target–disease evidence (filter to specific datasources):
QUERY = """
query Evidence($ensemblId: String!, $efoId: String!) {
disease(efoId: $efoId) {
evidences(ensemblIds: [$ensemblId],
datasourceIds: ["europepmc","ot_genetics_portal"]) {
count
rows { datasourceId score literature }
}
}
}
"""
Custom-weighted association scoring (e.g. "genetics-only"):
associatedTargets(
datasources: [
{ id: "ot_genetics_portal", weight: 1.0, propagate: true, required: true }
{ id: "europepmc", weight: 0.2, propagate: true, required: false }
]
) { rows { target { approvedSymbol } score } }
Drug profile (mechanism, indications, FAERS adverse events):
QUERY = """
query Drug($chemblId: String!) {
drug(chemblId: $chemblId) {
id name drugType maximumClinicalStage
mechanismsOfAction { rows { mechanismOfAction targetName actionType } }
indications { count rows { disease { id name } maxClinicalStage } }
adverseEvents(page: { index: 0, size: 10 }) {
count
rows { name count logLR }
}
}
}
"""
ot_query(QUERY, {"chemblId": "CHEMBL1201583"}) # bevacizumab
Variant annotation (consequence, allele frequencies, credible-set membership):
QUERY = """
query Variant($variantId: String!) {
variant(variantId: $variantId) {
id chromosome position referenceAllele alternateAllele rsIds
mostSevereConsequence { id label }
alleleFrequencies { populationName alleleFrequency }
transcriptConsequences {
target { id approvedSymbol }
variantConsequences { id label }
isEnsemblCanonical
}
}
}
"""
ot_query(QUERY, {"variantId": "19_44908822_C_T"}) # APOE rs7412
GWAS study metadata (root field study for one ID, studies for batch):
QUERY = """
query Study($studyId: String!) {
study(studyId: $studyId) {
id studyType traitFromSource pubmedId publicationFirstAuthor
nSamples nCases nControls
diseases { id name }
credibleSets(page: { index: 0, size: 10 }) {
count
rows { studyLocusId region pValueMantissa pValueExponent }
}
}
}
"""
ot_query(QUERY, {"studyId": "GCST005194"}) # CAD GWAS
Credible sets + L2G + colocalisation (the former "Genetics Portal" core query):
QUERY = """
query CredibleSets($studyIds: [String!]!) {
credibleSets(page: { index: 0, size: 25 }, studyIds: $studyIds) {
count
rows {
studyLocusId region
pValueMantissa pValueExponent
variant { id rsIds mostSevereConsequence { label } }
l2GPredictions { rows { target { id approvedSymbol } score } }
colocalisation { rows { otherStudyLocus { studyId } h4 clpp } }
}
}
}
"""
ot_query(QUERY, {"studyIds": ["GCST005194"]})
Step 4 — Iterate / paginate
List fields take page: { index, size }. Don't fetch thousands of rows in one call; if the user wants more, paginate or switch to bulk downloads.
Common Issues
| Issue | Solution |
|---|---|
HTTP 200 but errors in response |
GraphQL errors come back in the body, not as 4xx — always check payload["errors"] |
Cannot query field "X" on type "Y" |
Schema field name has changed; check the playground or run an introspection query |
Empty associatedTargets for a broad disease |
Add enableIndirect: true to roll up evidence from descendant ontology terms |
| Symbol/name not recognised | Run a search query first; the API only accepts standardised IDs (Ensembl/EFO/ChEMBL/GCST) |
| Truncated results | List fields are paginated — pass page: { index, size } and iterate |
| Slow or timing out across many IDs | Stop and switch to bulk downloads (FTP, BigQuery open-targets-prod, AWS) |
Looking for old api.genetics.opentargets.org endpoint |
Genetics data is now part of the main Platform API; use variant, study, credibleSet fields here |
Best Practices
- ✅ Resolve names → IDs once with
search, then cache the IDs - ✅ Request only the fields you need — GraphQL gives you exactly what you ask for
- ✅ Traverse the graph in a single query instead of chaining requests (e.g.
disease → associatedTargets → target { tractability }) - ✅ Always check
errorsin the response body — not just the HTTP status - ✅ Use
enableIndirect: truefor broad disease terms so descendant evidence is included - ✅ Paginate lists with
page: { index, size } - ⚠️ Hand off to bulk downloads when the user needs thousands of entities — the docs explicitly discourage looping the API
- ✅ Cite the data release version in any report (
meta { dataVersion { year month } })
Related Skills
- Bulk Open Targets data — for thousands of entities, use FTP/BigQuery/AWS downloads instead of this skill
- GWAS / variant annotation skills — for follow-up on variants returned here
- ChEMBL — for deeper drug/compound chemistry beyond what Open Targets exposes
- EuropePMC literature search — for the underlying papers behind text-mined evidence
References
Official documentation:
- API landing page: https://platform.opentargets.org/api
- API docs: https://platform-docs.opentargets.org/data-access/graphql-api
- GraphQL playground (with schema): https://api.platform.opentargets.org/api/v4/graphql/browser
- Schema dump: https://api.platform.opentargets.org/api/v4/graphql/schema
- Bulk data downloads: https://platform-docs.opentargets.org/data-access/datasets
- Community / example queries: https://community.opentargets.org/
Citation:
- Open Targets Platform: Ochoa et al., Nucleic Acids Research (most recent release paper)
License: Data CC0 1.0; API free to use.
Code preview
No Python/R preview files were found.
Companion files
| Type | Path | Bytes |
|---|---|---|
| Markdown | SKILL.md | 11,494 |
| JSON | skill.meta.json | 732 |