Clinical Trials Landscape
Map the trial landscape by mechanism, phase and sponsor.
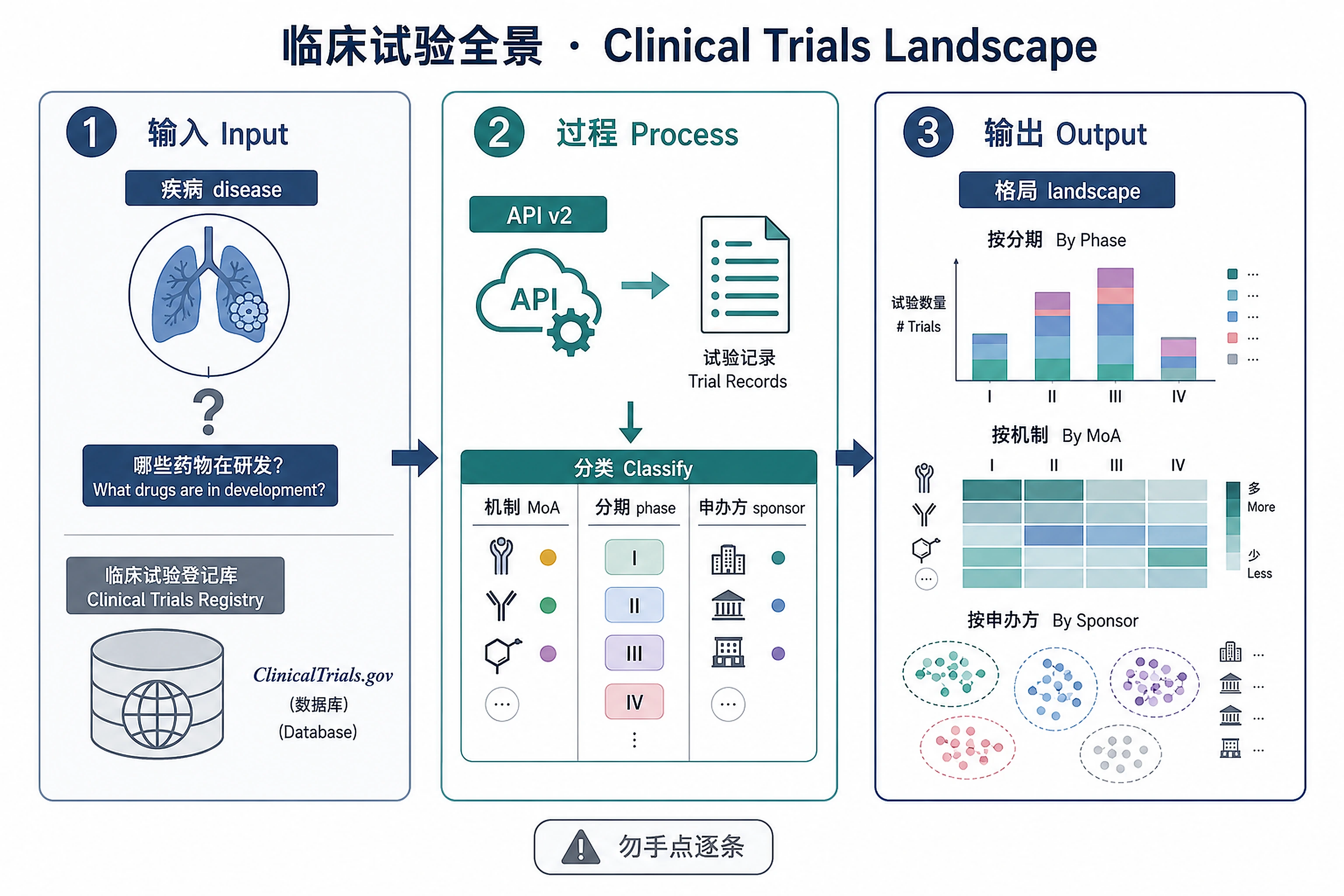
Overview
Problem. What's in development for a disease; what's the competition?
Learning goals
- Place findings in a clinical, industry context
- Programmatic queries: reproducible and updatable
Figures
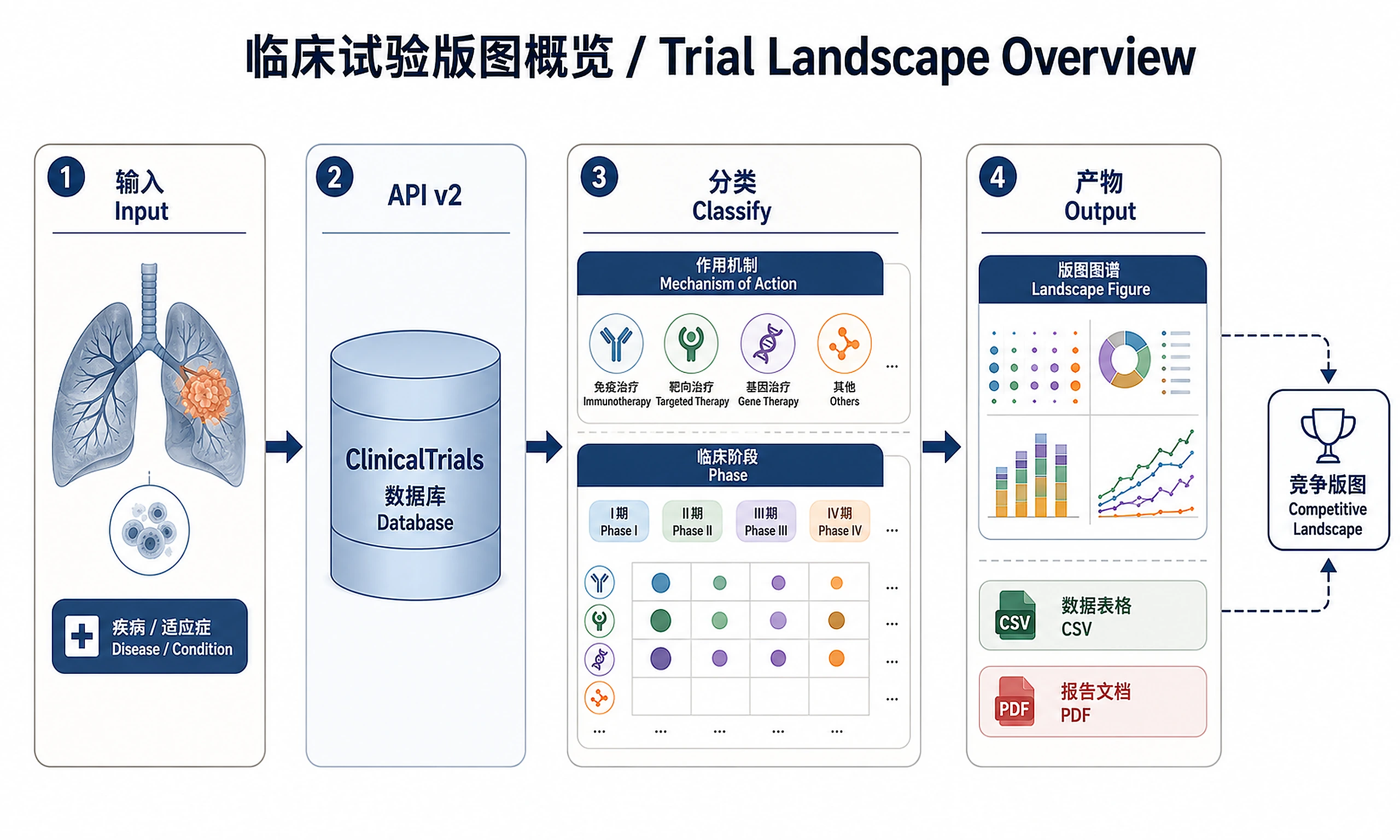
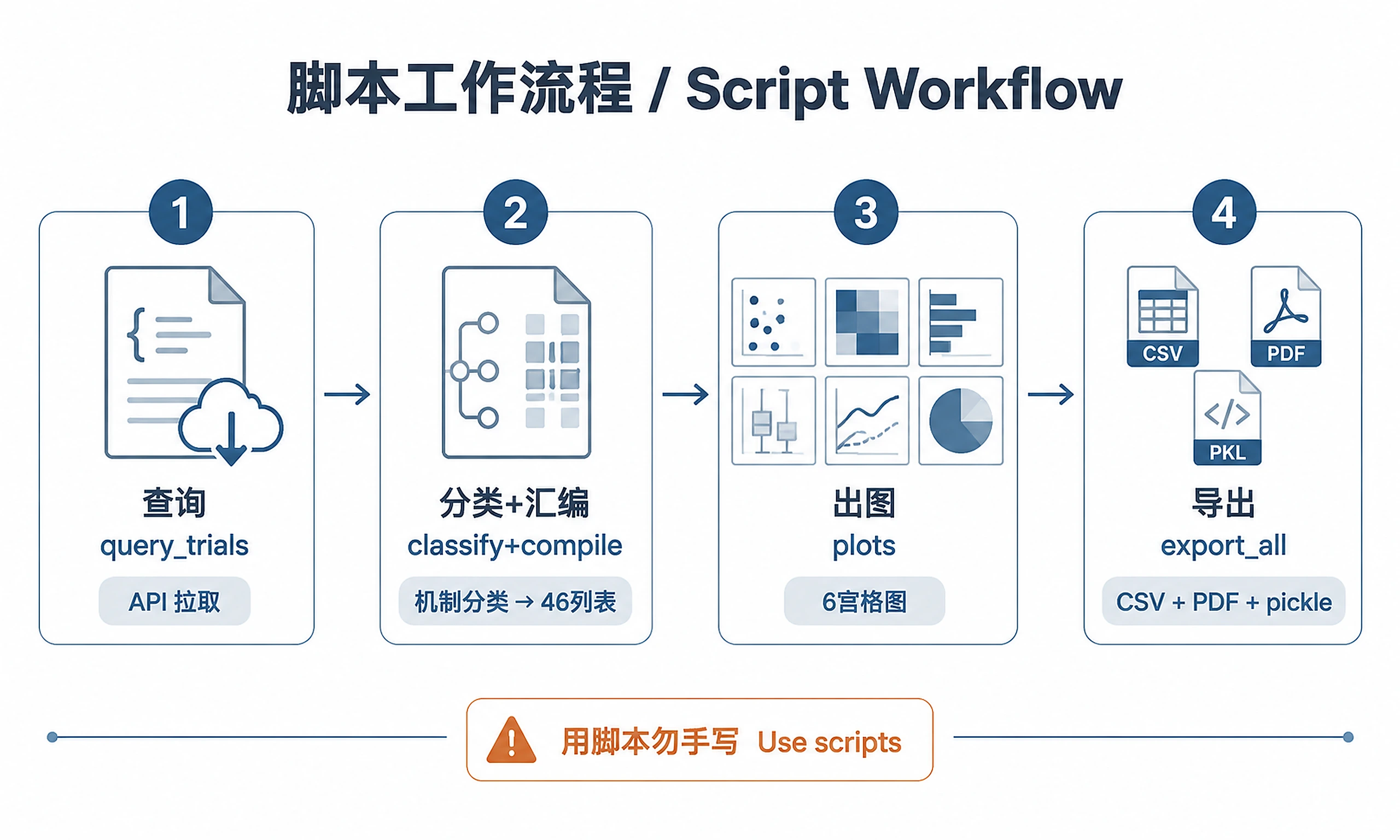
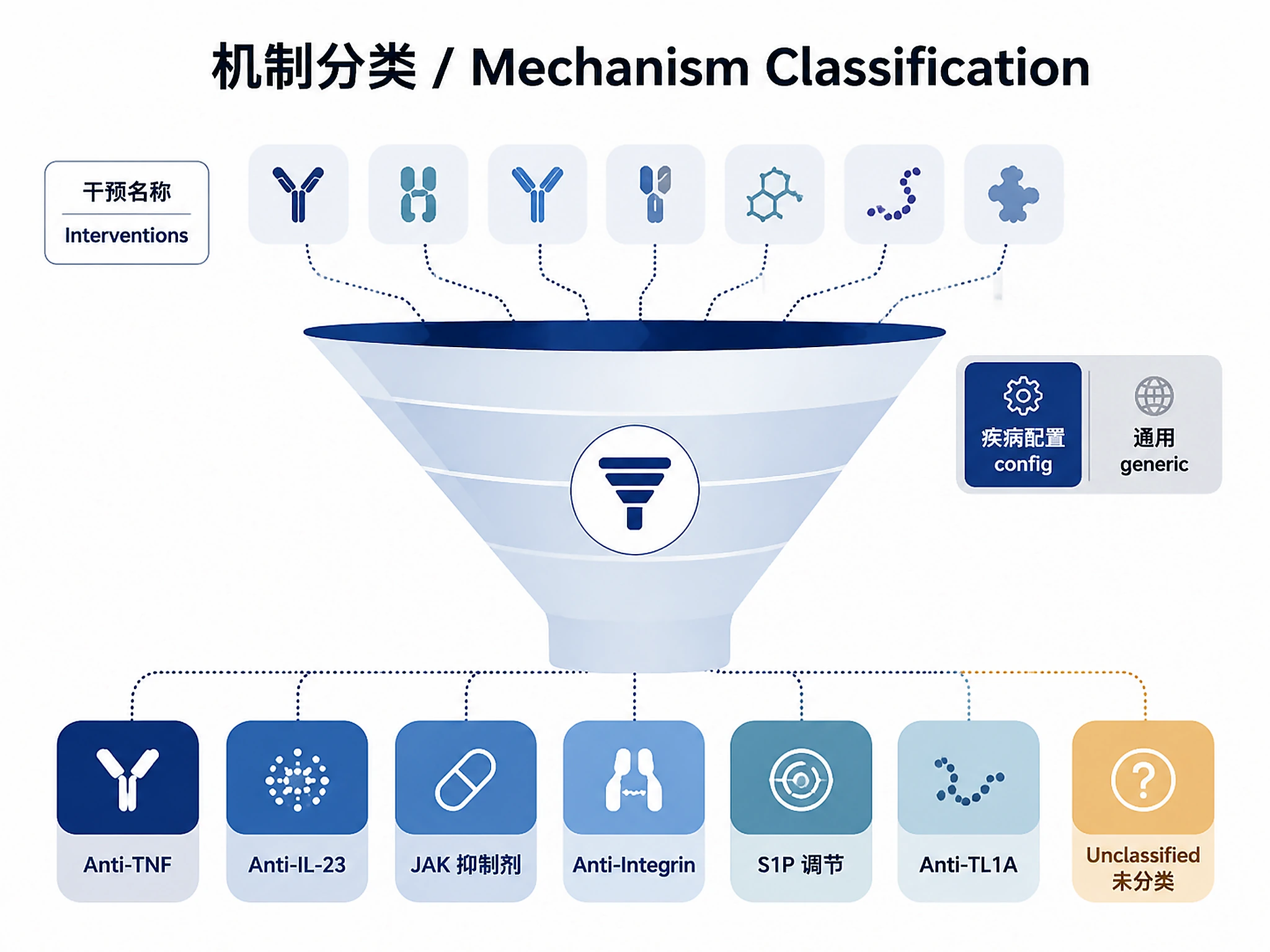
Tutorial
When to Use This Skill
- Map competitive landscape across therapeutic mechanisms for any disease
- Track specific mechanism classes (e.g., anti-IL23, anti-TL1A, JAK inhibitors)
- Identify sponsors and their pipeline positions by phase
- Phase distribution analysis for business development diligence
- Pipeline monitoring for a specific sponsor's disease portfolio
- Pre-built disease configs available (IBD with 14 mechanism classes); generic mode for any other disease
Do NOT use for:
- Detailed single-trial protocol analysis
- Efficacy/safety comparisons (requires literature review skill)
Installation
| Software | Version | License | Commercial Use | Installation |
|---|---|---|---|---|
| pandas | ≥1.3 | BSD-3 | ✅ Permitted | pip install pandas |
| requests | ≥2.25 | Apache-2.0 | ✅ Permitted | pip install requests |
| numpy | ≥1.20 | BSD-3 | ✅ Permitted | pip install numpy |
| plotnine | ≥0.10 | MIT | ✅ Permitted | pip install plotnine |
| plotnine-prism | ≥0.3 | MIT | ✅ Permitted | pip install plotnine-prism |
| seaborn | ≥0.11 | BSD-3 | ✅ Permitted | pip install seaborn |
| matplotlib | ≥3.4 | PSF | ✅ Permitted | pip install matplotlib |
| reportlab | ≥3.6 | BSD | ✅ Permitted | pip install reportlab |
| pyyaml | ≥5.0 | MIT | ✅ Permitted | pip install pyyaml |
pip install pandas requests numpy plotnine plotnine-prism seaborn matplotlib reportlab pyyaml
System requirements: Internet connection for ClinicalTrials.gov API calls.
Inputs
Required:
- Disease / condition terms — list of conditions to search ClinicalTrials.gov
Optional:
- Disease config — pre-built config ID (e.g.,
"ibd") for mechanism taxonomy, orNonefor generic - Mechanism filter — e.g., "Anti-IL-23 (p19)", "Anti-TL1A", "JAK Inhibitor"
- Sponsor filter — e.g., "Takeda", "AbbVie"
- Status filter — Default: all active (Recruiting + Active not recruiting + Not yet recruiting)
- Phase filter — Phase 1, 2, 3, 4
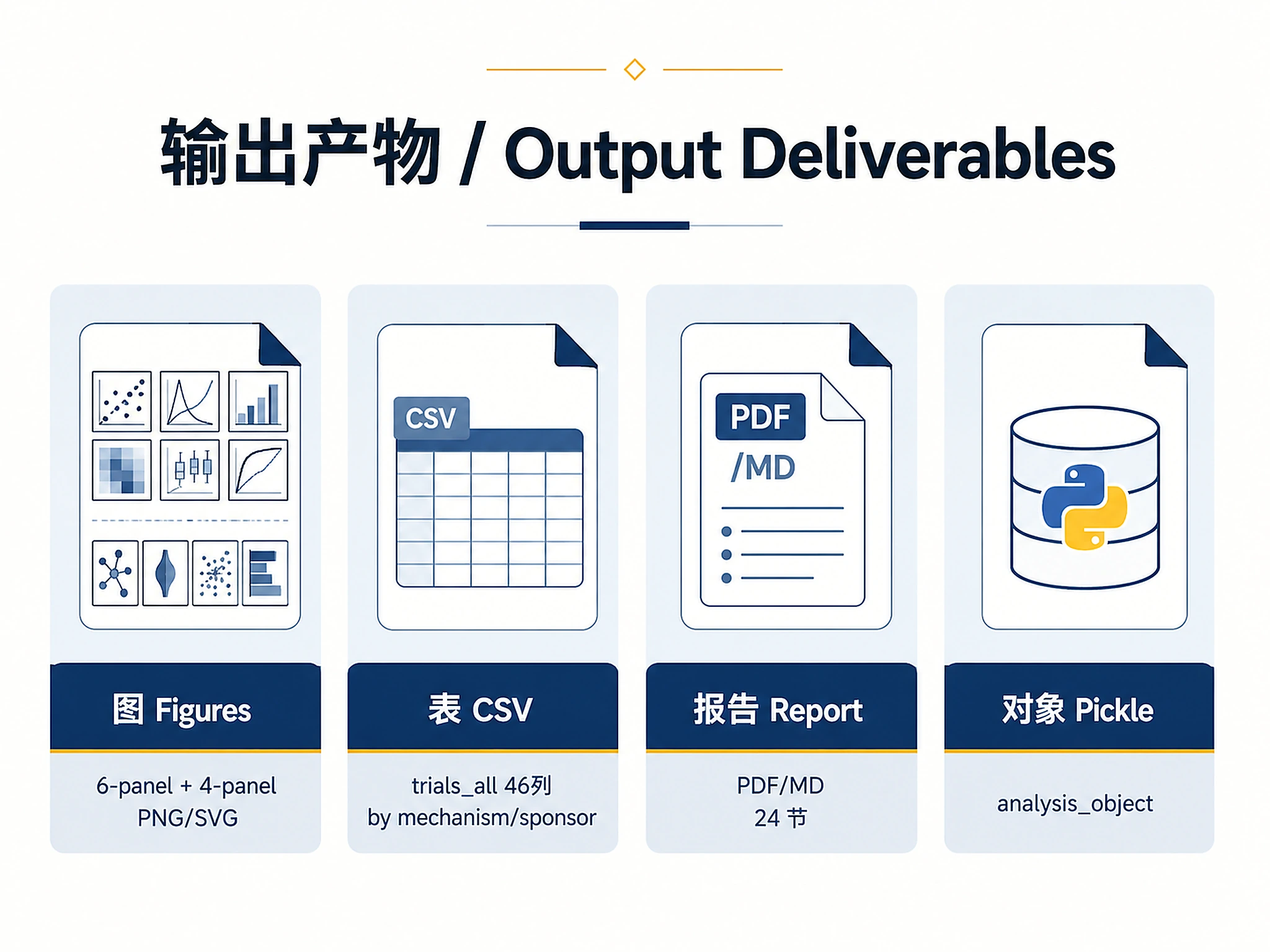
Outputs
Visualizations (PNG + SVG):
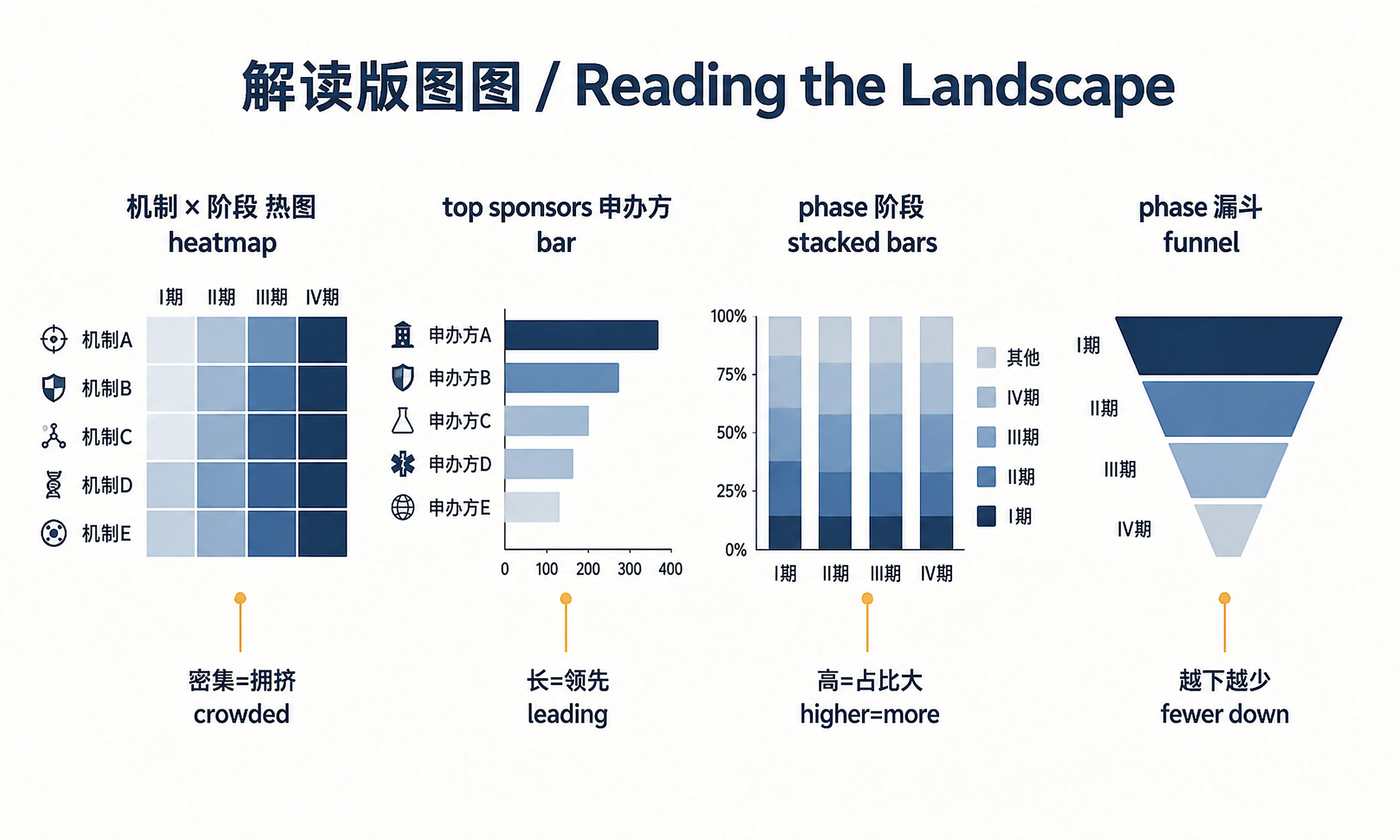
landscape_overview.png/.svg— 6-panel landscape figure (300 DPI)- Mechanism × Phase heatmap, top sponsors, phase stacked bars, mechanism counts, timeline, sponsor type
landscape_supplementary.png/.svg— 4-panel supplementary figure- Top 15 countries, study design by phase, enrollment distribution, phase transition funnel
Results (CSV):
trials_all.csv— All trials with 46 columns (mechanism, phase, sponsor, geography, study design, arms, endpoints, eligibility, regulatory)trials_by_mechanism.csv— Mechanism × phase cross-tabulationtrials_by_sponsor.csv— Sponsor summary with trial countstrials_filtered.csv— Filtered subset (if mechanism/sponsor filter applied)
Reports:
landscape_report.pdf— Publication-quality PDF with 24 sections: executive summary, mechanism deep-dives, geographic landscape, study design, phase transition funnel, endpoint comparison, combination therapies, biosimilar assessment, whitespace analysis, and morelandscape_report.md— Markdown version with identical 24-section structure
Analysis objects (Pickle):
analysis_object.pkl— Complete landscape for downstream use- Load with:
import pickle; obj = pickle.load(open('analysis_object.pkl', 'rb')) - Contains: trials_df (46 columns), mechanism/phase/sponsor distributions, geographic stats, design stats, parameters
Clarification Questions
-
Data Source (ASK THIS FIRST):
- This skill queries the ClinicalTrials.gov API v2 directly (free, no key needed).
- Use live API data? (recommended, ~30 seconds)
- Or use cached demo data? Pre-loaded IBD landscape snapshot for quick demo
-
Disease Area:
- Which disease area to analyze?
- a) IBD (Inflammatory Bowel Disease) — pre-built config with 14 mechanism classes
- b) Oncology (generic intervention-type classification)
- c) Autoimmune / Rheumatology (generic classification)
- d) Other (specify disease and condition terms)
-
Scope (if IBD selected): - Which conditions?
- a) All IBD (Crohn's, UC, and IBD unspecified) — recommended
- b) Crohn's Disease only
- c) Ulcerative Colitis only
- (If other disease) — Provide list of condition search terms
-
Focus:
- Any mechanism or sponsor to highlight?
- (IBD) a) Anti-IL-23 — recommended for demo | b) Anti-TL1A | c) All mechanisms
- (Other) Specify or skip highlighting
Standard Workflow
🚨 MANDATORY: USE SCRIPTS EXACTLY AS SHOWN - DO NOT WRITE INLINE CODE 🚨
Step 1 — Load config and query ClinicalTrials.gov:
import sys; sys.path.insert(0, ".")
from scripts.disease_config import load_disease_config, get_default_conditions
from scripts.query_clinicaltrials import query_trials
# Load disease config (use "ibd" for IBD, or None for generic)
config = load_disease_config("ibd")
# Get conditions from config or specify manually
conditions = get_default_conditions(config) or ["Crohn's Disease", "Ulcerative Colitis", "Inflammatory Bowel Disease"]
raw_trials = query_trials(
conditions=conditions,
statuses=["RECRUITING", "ACTIVE_NOT_RECRUITING", "ENROLLING_BY_INVITATION", "NOT_YET_RECRUITING"],
)
✅ VERIFICATION: "✓ Retrieved {N} trials from ClinicalTrials.gov"
Step 2 — Classify and compile:
from scripts.classify_mechanisms import classify_all
from scripts.compile_trials import compile_trials
classified = classify_all(raw_trials, config=config)
trials_df = compile_trials(classified, output_dir="landscape_results")
DO NOT write inline classification code. The script loads mechanism taxonomy from config.
✅ VERIFICATION: "✓ Trial data compiled successfully!"
Step 3 — Generate visualizations:
from scripts.generate_landscape_plots import generate_landscape_plots
generate_landscape_plots(
trials_df,
output_dir="landscape_results",
highlight_mechanism="Anti-IL-23 (p19)", # or None for no highlight
highlight_sponsor=None, # or "Takeda" to highlight
config=config,
)
DO NOT write inline plotting code. The script handles all 6 panels + PNG/SVG export.
✅ VERIFICATION: "✓ All landscape visualizations generated successfully!"
Step 4 — Export results:
from scripts.export_all import export_all
export_all(
trials_df,
parameters={
"conditions": conditions,
"statuses": ["RECRUITING", "ACTIVE_NOT_RECRUITING", "ENROLLING_BY_INVITATION", "NOT_YET_RECRUITING"],
"highlight_mechanism": "Anti-IL-23 (p19)",
},
output_dir="landscape_results",
config=config,
)
DO NOT write custom export code. Use export_all().
✅ VERIFICATION: "=== Export Complete ==="
⚠️ CRITICAL — DO NOT:
- ❌ Write inline classification code → STOP: Use
classify_all()from scripts - ❌ Write inline plotting code (ggplot, plt, sns) → STOP: Use
generate_landscape_plots() - ❌ Write custom export code → STOP: Use
export_all() - ❌ Try to scrape ClinicalTrials.gov HTML → Use the API via
query_trials()
⚠️ IF SCRIPTS FAIL — Script Failure Hierarchy:
- Fix and Retry (90%) — Install missing package, re-run script
- Modify Script (5%) — Edit the script file itself, document changes
- Use as Reference (4%) — Read script, adapt approach, cite source
- Write from Scratch (1%) — Only if genuinely impossible, explain why
NEVER skip directly to writing inline code without trying the script first.
Common Issues
| Error | Cause | Solution |
|---|---|---|
| ConnectionError / Timeout | ClinicalTrials.gov unreachable | Check internet connection; retry after 30 seconds |
| HTTP 429 Too Many Requests | Rate limit exceeded | Increase RATE_LIMIT_DELAY in query_clinicaltrials.py |
| ModuleNotFoundError: plotnine | Missing visualization package | pip install plotnine plotnine-prism |
| Empty results (0 trials) | Overly restrictive filters | Broaden condition/status/phase filters |
| Many "Unclassified" mechanisms | No disease config or new drugs | Use a disease config (e.g., "ibd") or update disease_configs/*.yaml |
| SVG export failed | Missing SVG backend | Normal — PNG is always generated as fallback |
| Sponsor name variants | Same company, different names | Update SPONSOR_NORMALIZATION in compile_trials.py |
| ModuleNotFoundError: yaml | Missing pyyaml | pip install pyyaml |
Interpretation Guidelines
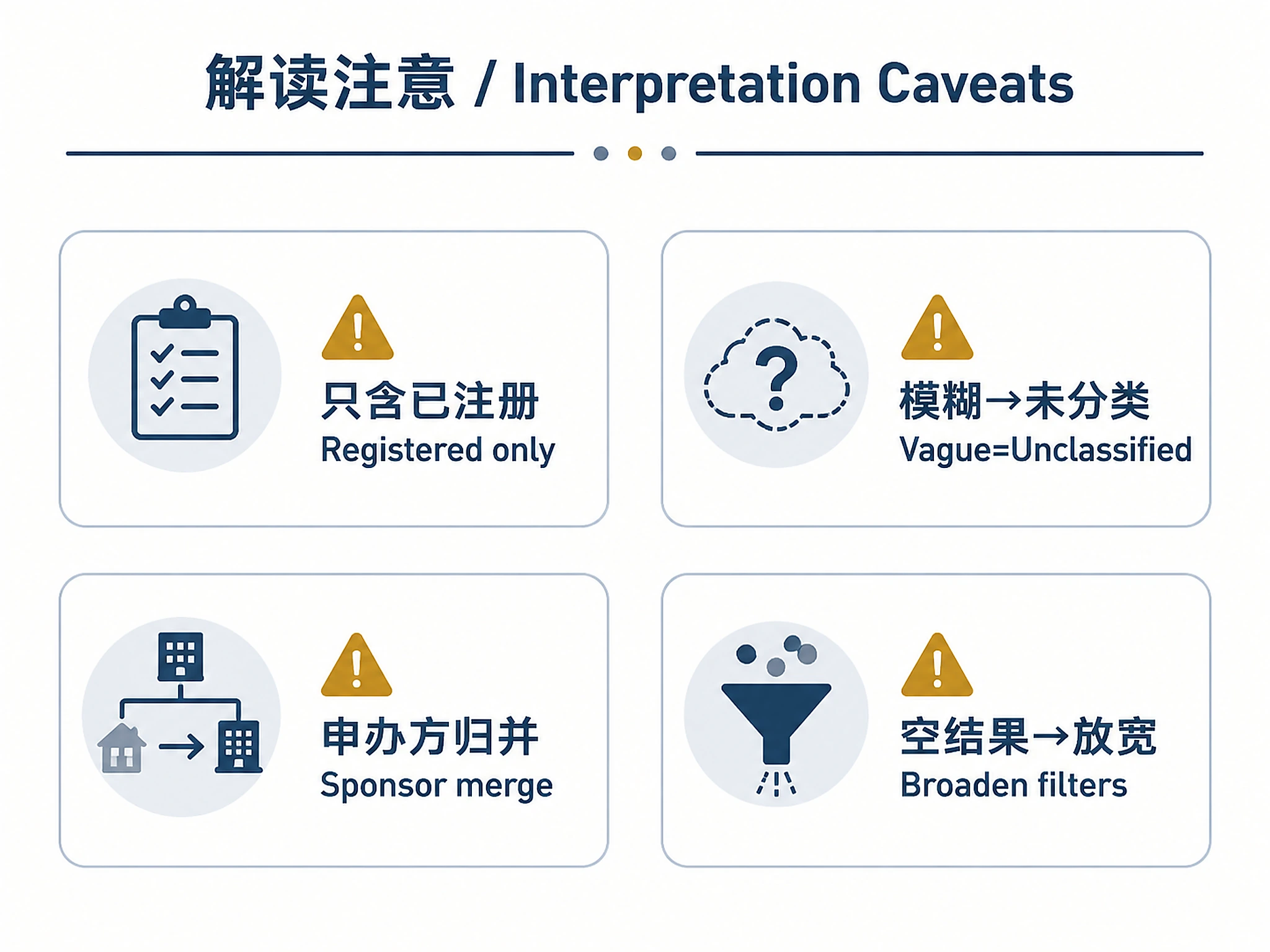
- Mechanism classification is based on intervention names and descriptions — some trials with vague descriptions (e.g., "Study Drug") will be classified as "Other Biologic" or "Unclassified"
- Phase 2/3 indicates a combined Phase 2/3 study design
- Sponsor normalization groups subsidiaries under parent company (e.g., Millennium → Takeda)
- Industry vs Academic based on ClinicalTrials.gov
leadSponsor.classfield - The landscape reflects registered trials, not all pipeline programs (pre-IND programs won't appear)
- Disease configs provide curated mechanism taxonomies; without config, classification uses generic intervention types
Suggested Next Steps
- Deep-dive a mechanism — Use
literature-preclinicalto review mechanism biology - Track a sponsor's full pipeline — Use
development-landscapefor broader pipeline view - Biomarker analysis — Use
lasso-biomarker-panelto identify response biomarkers from trial data - Export to presentation — Use landscape_report.md and plots for stakeholder review
Related Skills
development-landscape— Broader, multi-source pipeline landscape for any targetliterature-preclinical— Literature review for mechanism biologylasso-biomarker-panel— Biomarker discovery from expression data
References
- ClinicalTrials.gov API v2: https://clinicaltrials.gov/data-api/api
- ClinicalTrials.gov: https://clinicaltrials.gov/
- See
references/api-parameters.mdfor full API parameter reference - See
references/mechanisms.mdfor mechanism taxonomy details - See
references/output-schema.mdfor output column definitions
Code preview
scripts/__init__.py
# clinicaltrials-landscape scripts packagescripts/classify_mechanisms.py
"""
Classify clinical trial interventions by mechanism of action.
Supports config-driven taxonomy (disease-specific patterns loaded from
disease_configs/*.yaml) and generic fallback classification by
intervention type when no config is available.
"""
import re
try:
from disease_config import get_mechanism_patterns, get_drug_normalization
except ImportError:
from scripts.disease_config import get_mechanism_patterns, get_drug_normalization
# ============================================================
# MODULE-LEVEL STATE (set by configure())
# ============================================================
# Taxonomy and drug normalization loaded from disease config.
# When empty, classify_mechanism() uses generic intervention-type fallback.
_mechanism_patterns = []
_drug_normalization = {}
_configured = False
def configure(config):
"""
Load mechanism taxonomy and drug normalization from disease config.
Parameters
----------
config : dict or None
Parsed disease config from load_disease_config().
If None, clears taxonomy (uses generic fallback).
"""
global _mechanism_patterns, _drug_normalization, _configured
_mechanism_patterns = get_mechanism_patterns(config)
_drug_normalization = get_drug_normalization(config)
_configured = True
# Phase normalization mapping
PHASE_MAP = {
"EARLY_PHASE1": "Phase 1",
"PHASE1": "Phase 1",
"PHASE2": "Phase 2",
"PHASE3": "Phase 3",
"PHASE4": "Phase 4",
"NA": "Not Applicable",
}
def _normalize_drug_name(name):
"""Normalize drug name to canonical form using loaded config."""
if not name:
return name
for pattern, canonical in _drug_normalization.items():
if re.match(pattern, name.strip()):
return canonical
return name.strip()
def _is_biosimilar(interventions, brief_title="", official_title=""):
"""Detect if a trial involves a biosimilar product."""
corpus = " ".join([
*[intv.get("name", "") + " " + intv.get("description", "") for intv in interventions],
brief_title, official_title
]).lower()
biosimilar_patterns = [
"biosimilar", "ct-p13", "sb2", "sb5", "abp 501", "gp2017",
"remsima", "inflectra", "renflexis", "avsola", "ixifi",
"hadlima", "hyrimoz", "cyltezo", "amjevita", "idacio",
"similar biologic", "proposed biosimilar",
]
return any(p in corpus for p in biosimilar_patterns)
def classify_mechanism(interventions, brief_title="", official_title=""):scripts/compile_trials.py
"""
Compile, deduplicate, and structure clinical trial data (Step 2b).
Produces a clean DataFrame with normalized phases, mechanisms,
sponsor names, enrollment cleaning, and enriched fields from
the API (geography, study design, arms, endpoints, eligibility).
Deduplicates by NCT ID.
"""
import os
import re
import pandas as pd
import numpy as np
# Sponsor normalization: maps lowercase substrings to canonical names
SPONSOR_NORMALIZATION = {
"takeda": "Takeda",
"takeda pharmaceutical": "Takeda",
"takeda development center": "Takeda",
"millennium pharmaceuticals": "Takeda",
"abbvie": "AbbVie",
"johnson & johnson": "J&J / Janssen",
"janssen": "J&J / Janssen",
"janssen research": "J&J / Janssen",
"janssen-cilag": "J&J / Janssen",
"janssen biotech": "J&J / Janssen",
"eli lilly": "Eli Lilly",
"lilly": "Eli Lilly",
"pfizer": "Pfizer",
"bristol-myers squibb": "Bristol-Myers Squibb",
"bristol myers squibb": "Bristol-Myers Squibb",
"gilead": "Gilead Sciences",
"gilead sciences": "Gilead Sciences",
"roche": "Roche / Genentech",
"genentech": "Roche / Genentech",
"astrazeneca": "AstraZeneca",
"novartis": "Novartis",
"amgen": "Amgen",
"merck sharp": "Merck / MSD",
"merck & co": "Merck / MSD",
"msd": "Merck / MSD",
"sanofi": "Sanofi",
"regeneron": "Regeneron",
"boehringer ingelheim": "Boehringer Ingelheim",
"arena pharmaceuticals": "Arena / Pfizer",
"celgene": "Bristol-Myers Squibb",
"galapagos": "Galapagos",
"prometheus biosciences": "Merck / MSD",
"teva": "Teva",
"teva branded": "Teva",
"teva pharmaceutical": "Teva",
}
# Phase numeric ordering
PHASE_NUMERIC = {
"Phase 1": 1,
"Phase 1/2": 1.5,
"Phase 2": 2,
"Phase 2/3": 2.5,
"Phase 3": 3,
"Phase 3/4": 3.5,
"Phase 4": 4,
"Not Applicable": 0,
}
# Region mapping for geographic analysis
COUNTRY_TO_REGION = {
# North America
"United States": "North America", "Canada": "North America", "Mexico": "North America",
# Western Europe
"United Kingdom": "Western Europe", "Germany": "Western Europe", "France": "Western Europe",
"Italy": "Western Europe", "Spain": "Western Europe", "Netherlands": "Western Europe",
"Belgium": "Western Europe", "Switzerland": "Western Europe", "Austria": "Western Europe",
"Ireland": "Western Europe", "Sweden": "Western Europe", "Denmark": "Western Europe",
"Norway": "Western Europe", "Finland": "Western Europe", "Portugal": "Western Europe",
"Greece": "Western Europe", "Luxembourg": "Western Europe",
# Eastern Europe
"Poland": "Eastern Europe", "Czech Republic": "Eastern Europe", "Czechia": "Eastern Europe",
"Hungary": "Eastern Europe", "Romania": "Eastern Europe", "Bulgaria": "Eastern Europe",Companion files
| Type | Path | Bytes |
|---|---|---|
| Markdown | references/api-parameters.md | 5,684 |
| Markdown | references/mechanisms.md | 5,047 |
| Markdown | references/output-schema.md | 7,461 |
| Python | scripts/__init__.py | 43 |
| Python | scripts/classify_mechanisms.py | 11,773 |
| Python | scripts/compile_trials.py | 22,885 |
| Python | scripts/disease_config.py | 4,799 |
| Python | scripts/export_all.py | 9,705 |
| Python | scripts/generate_landscape_plots.py | 26,198 |
| Python | scripts/generate_pdf_report.py | 63,886 |
| Python | scripts/generate_report.py | 83,351 |
| Python | scripts/query_clinicaltrials.py | 10,621 |
| Markdown | SKILL.md | 10,441 |
| JSON | skill.meta.json | 2,618 |